

Usage
Headless mode
Several commands in the Amplify CLI support arguments which could potentially be used in your CI/CD flows. The Amplify CLI arguments are not just simple strings, but also JSON objects containing information that the CLI would otherwise gather through prompts. The CLI will not prompt for input (work non-interactively) if the information it seeks is provided by an argument.
Arguments are used mostly for scripting so that the command execution flow is not interrupted by prompts. Examples for this could be found here
--yes flag
The --yes flag, or its alias -y, suppresses command line prompts if defaults are available, and uses the defaults in command execution.
The following commands take the --yes flag:
amplify initamplify configure projectamplify pushamplify publishamplify pull
amplify init parameters
The ampify init command takes these parameters:
--amplify--frontend--providers--yes--app
--amplify
Contains basic information of the project, it has these keys:
projectName: the name of the project under developmentappId: the Amplify Service project Id (optional, see below)envName: the name of your first environmentdefaultEditor: your default code editor
The appId parameter is optional and it is used in two use cases.
- Amplify Service uses it internally when you initialize a project on Amplify web console.
- For project migrations. For projects initialized by Amplify CLI version prior to 4.0.0, no Amplify Service project is created online to track the backend environment’s resources. The latest version of the Amplify CLI will create a new Amplify Service project for them in the post-push check. If you wanted to add the backend environment to an existing Amplify Service project instead of creating a new one, you can run
amplify initagain, and provide theappIdinside the--amplifyparameter, or explicitly asamplify init --appId <Amplify-Service-Project-AppId>.
--frontend
Contains information for the CLI’s frontend plugin, it has these keys:
frontend: the name of the chosen frontend plugin (without theamplify-frontend-prefix).framework: the frontend framework used in the project, such asreact. Only thejavascriptfrontend handler takes it.config: the configuration settings for the frontend plugin.
There are currently three official frontend plugins, and the following are the specifications of their respective config object:
config for javascript
SourceDir: The project’s source directory. The CLI will place and update theaws-exports.jsfile in it, theaws-exports.jsfile is used to configure theAmplify JSlibrary.DistributionDir: The project’s distribution directory, where the build artifacts are stored. The CLI will upload the contents inside this directory to the S3 hosting buckets in the execution of theamplify publishcommand.BuildCommand: The build command for the project. The CLI invokes the build command before uploading the contents in the distribution directory in the execution of theamplify publishcommand.StartCommand: The start command for the project, used for local testing. The CLI invokes the start command after it has pushed the latest development of the backend to the cloud in the execution of theamplify runcommand.
config for android
ResDir: The Android project’s resource directory, such asapp/src/main/res.
config for ios
The ios frontend handler does NOT take the config object.
--providers
Contains configuration settings for provider plugins. The key is the name of the provider plugin (without the amplify-provider- prefix), and the value is its configuration. Provider plugins contained in this object will be initialized, and able to provide functionalities for creation and maintenance of the cloud resources.
Currently there is only one official provider plugin: amplify-provider-awscloudformation, its configuration is for the CLI to resolve aws credentials and region, the following are the specifications:
configLevel: The configuration level is eitherprojectorgeneral. Unless explicitly set togeneral, theprojectlevel is chosen.generallevel means the CLI will not manage configuration at the project level, it instead relies on the AWS SDK to resolve aws credentials and region. To learn how it works, check the AWS SDK’s documents on credentials and region.projectlevel means the configuration is managed at the project level by the CLI, each project gets its own independent configuration. The following attributes are used only when the configuration is at project leveluseProfile: A boolean indicating whether to use a profile defined in the shared config file (~/.aws/config) and credentials file (~/.aws/credentials).profileName: The name of the profile ifuseProfileis set to true.accessKeyId: The aws access key id ifuseProfileis set to false.secretAccessKey: The aws secret access key ifuseProfileis set to false.region: The aws region ifuseProfileis set to false.
--app
Installs, initializes, and provisions resources for a sample amplify application from the provided GitHub repository URL. This option must be executed in an empty directory. The sample repository must have an amplify folder, including the following:
project-config.jsonin .config folderbackend-config.jsonin backend folder- The necessary cloudformation files in the backend folder
- e.g. stacks,
schema.graphqlfor api - e.g. cloudformation template for auth
- e.g. stacks,
- local files local-env.json and local-aws-info.json are NOT required
If the repository contains a yarn.lock and/or package.json file, the sample will be installed with the corresponding package manager and started after resources have been provisioned.
Sample script
#!/bin/bash
set -e
IFS='|'
REACTCONFIG="{\
\"SourceDir\":\"src\",\
\"DistributionDir\":\"build\",\
\"BuildCommand\":\"npm run-script build\",\
\"StartCommand\":\"npm run-script start\"\
}"
AWSCLOUDFORMATIONCONFIG="{\
\"configLevel\":\"project\",\
\"useProfile\":false,\
\"profileName\":\"default\",\
\"accessKeyId\":\"headlessaccesskeyid\",\
\"secretAccessKey\":\"headlesssecrectaccesskey\",\
\"region\":\"us-east-1\"\
}"
AMPLIFY="{\
\"projectName\":\"headlessProjectName\",\
\"envName\":\"myenvname\",\
\"defaultEditor\":\"code\"\
}"
FRONTEND="{\
\"frontend\":\"javascript\",\
\"framework\":\"react\",\
\"config\":$REACTCONFIG\
}"
PROVIDERS="{\
\"awscloudformation\":$AWSCLOUDFORMATIONCONFIG\
}"
amplify init \
--amplify $AMPLIFY \
--frontend $FRONTEND \
--providers $PROVIDERS \
--yes
amplify configure project parameters
The amplify configure project command allows the user to change the configuration settings that were first set by amplify init, and it takes the same parameters as the amplify init command:
--amplify--frontend--providers--yes
Sample script
#!/bin/bash
set -e
IFS='|'
REACTCONFIG="{\
\"SourceDir\":\"src\",\
\"DistributionDir\":\"build\",\
\"BuildCommand\":\"npm run-script build\",\
\"StartCommand\":\"npm run-script start\"\
}"
AWSCLOUDFORMATIONCONFIG="{\
\"configLevel\":\"project\",\
\"useProfile\":false,\
\"profileName\":\"default\",\
\"accessKeyId\":\"headlessaccesskeyid\",\
\"secretAccessKey\":\"headlesssecrectaccesskey\",\
\"region\":\"us-east-1\"\
}"
AMPLIFY="{\
\"projectName\":\"headlessProjectName\",\
\"defaultEditor\":\"code\"\
}"
FRONTEND="{\
\"frontend\":\"javascript\",\
\"framework\":\"react\",\
\"config\":$REACTCONFIG\
}"
PROVIDERS="{\
\"awscloudformation\":$AWSCLOUDFORMATIONCONFIG\
}"
amplify configure project \
--amplify $AMPLIFY \
--frontend $FRONTEND \
--providers $PROVIDERS \
--yes
amplify push/publish parameters
The amplify publish command internally executes amplify push so it takes the same parameters as push command. The amplify push command takes the following parameters
--codegen--yes
--codegen
Contains configuration for AppSync codegen, the following are the specifications:
generateCode:
A boolean indicating if to generate code for your GraphQL API.codeLanguage:
The targeted language of the generated code, such asjavascript.fileNamePattern:
The file name pattern of GraphQL queries, mutations and subscriptions.generatedFileName:
The file name for the generated code.generateDocs:
A boolean indicating whether to generate GraphQL statements (queries, mutations and subscription) based on the GraphQL schema types. The generated version will overwrite the current GraphQL queries, mutations and subscriptions.
Sample script
#!/bin/bash
set -e
IFS='|'
CODEGEN="{\
\"generateCode\":true,\
\"codeLanguage\":\"javascript\",\
\"fileNamePattern\":\"src/graphql/**/*.js\",\
\"generatedFileName\":\"API\",\
\"generateDocs\":true\
}"
amplify push \
--codegen $CODEGEN \
--yes
amplify pull parameters
The amplify pull command pulls down the latest backend environment to your local development.
It is used in two scenarios:
- On projects already initialized by the Amplify CLI, it pulls down the latest from the Cloud and updates the contents in the
amplify/#current-cloud-backenddirectory. The command does not take any parameters when used in this scenario. - On projects NOT yet initialized by the Amplify CLI, it pulls down a particular backend environment, and “attaches” it to the project. It will fully set up the
amplifydirectory for the project. The backend environment being pulled is specified byappIdandenvNamein theamplifyparameter (see below). The command takes the following parameters when used in this scenario.--amplify--frontend--providers--yes
--amplify
Contains basic information of the project, it has these keys:
projectName: the name of the project under developmentappId: the Amplify Service project IdenvName: the name of the backend environment in the above mention Amplify Service that you want to pull downdefaultEditor: your default code editor
--frontend
Contains information for the CLI’s frontend plugin, it has these keys:
frontend: the name of the chosen frontend plugin (without theamplify-frontend-prefix).framework: the frontend framework used in the project, such asreact. Only thejavascriptfrontend handler takes it.config: the configuration settings for the frontend plugin.
There are currently three official frontend plugins, and the following are the specifications of their respective config object:
config for javascript
SourceDir: The project’s source directory. The CLI will place and update theaws-exports.jsfile in it, theaws-exports.jsfile is used to configure theAmplify JSlibrary.DistributionDir: The project’s distribution directory, where the build artifacts are stored. The CLI will upload the contents inside this directory to the S3 hosting buckets in the execution of theamplify publishcommand.BuildCommand: The build command for the project. The CLI invokes the build command before uploading the contents in the distribution directory in the execution of theamplify publishcommand.StartCommand: The start command for the project, used for local testing. The CLI invokes the start command after it has pushed the latest development of the backend to the cloud in the execution of theamplify runcommand.
config for android
ResDir: The Android project’s resource directory, such asapp/src/main/res.
config for ios
The ios frontend handler does NOT take the config object.
--providers
The pull command is tied to the official provider plugin: amplify-provider-awscloudformation to pull down and attach a backend environment to your frontend project.
configLevel: The configuration level is eitherprojectorgeneral. Unless explicitly set togeneral, theprojectlevel is chosen.generallevel means the CLI will not manage configuration at the project level, it instead relies on the AWS SDK to resolve aws credentials and region. To learn how it works, check the AWS SDK’s documents on credentials and region.projectlevel means the configuration is managed at the project level by the CLI, each project gets its own independent configuration. The following attributes are used only when the configuration is at project leveluseProfile: A boolean indicating whether to use a profile defined in the shared config file (~/.aws/config) and credentials file (~/.aws/credentials).profileName: The name of the profile ifuseProfileis set to true.accessKeyId: The aws access key id ifuseProfileis set to false.secretAccessKey: The aws secret access key ifuseProfileis set to false.region: The aws region ifuseProfileis set to false.
Sample script
#!/bin/bash
set -e
IFS='|'
REACTCONFIG="{\
\"SourceDir\":\"src\",\
\"DistributionDir\":\"build\",\
\"BuildCommand\":\"npm run-script build\",\
\"StartCommand\":\"npm run-script start\"\
}"
AWSCLOUDFORMATIONCONFIG="{\
\"configLevel\":\"project\",\
\"useProfile\":false,\
\"profileName\":\"default\",\
\"accessKeyId\":\"headlessaccesskeyid\",\
\"secretAccessKey\":\"headlesssecrectaccesskey\",\
\"region\":\"us-east-1\"\
}"
AMPLIFY="{\
\"projectName\":\"headlessProjectName\",\
\"appId\":\"amplifyServiceProjectAppId\",\
\"envName\":\"myenvname\",\
\"defaultEditor\":\"code\"\
}"
FRONTEND="{\
\"frontend\":\"javascript\",\
\"framework\":\"react\",\
\"config\":$REACTCONFIG\
}"
PROVIDERS="{\
\"awscloudformation\":$AWSCLOUDFORMATIONCONFIG\
}"
amplify pull \
--amplify $AMPLIFY \
--frontend $FRONTEND \
--providers $PROVIDERS \
--yes
Upgrading the CLI
The Amplify CLI team continuously pushes new features, enhancements and security improvements and it is recommended to update the Amplify CLI version which you or your team is using to the latest version. You can keep track of the latest releases of the Amplify CLI on npm - https://www.npmjs.com/package/@aws-amplify/cli . Follow the steps below to update to the latest version of the CLI:
- Enter the following command in your terminal: <npm install -g @aws-amplify/cli>.
- Verify the successful installation of the latest CLI version by entering the following command in the CLI <amplify -v> and confirm the installed version of the Amplify CLI. You can find the latest version of the CLI here - https://www.npmjs.com/package/@aws-amplify/cli
- Navigate to your Amplify project folder using the following command cd
. To verify if it is a valid Amplify project folder, enter the following command in the CLI: . If it is a valid Amplify project folder, Amplify will display a list of the resources in the project folder that you have deployed to the AWS cloud. - Update your backend resources with updated security configurations or improvements by entering the following command in the CLI: <amplify push –force> . Hit Enter or type Y when prompted for confirmations. Look for this result <✔ All resources are updated in the cloud> to validate the configuration updates have been applied.
- If you have multiple AWS Amplify project folders, repeat steps #3 and #4 for each project folder.
IAM Policy for the CLI
The Amplify CLI requires the below IAM policies for performing actions across all categories. You can grant or restrict category permissions by including or removing items from the Action section as appropriate. For example, if you wish to restrict operations on the Auth category you can remove any of the lines starting with cognito.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"appsync:*",
"apigateway:POST",
"apigateway:DELETE",
"apigateway:PATCH",
"apigateway:PUT",
"cloudformation:CreateStack",
"cloudformation:CreateStackSet",
"cloudformation:DeleteStack",
"cloudformation:DeleteStackSet",
"cloudformation:DescribeStackEvents",
"cloudformation:DescribeStackResource",
"cloudformation:DescribeStackResources",
"cloudformation:DescribeStackSet",
"cloudformation:DescribeStackSetOperation",
"cloudformation:DescribeStacks",
"cloudformation:UpdateStack",
"cloudformation:UpdateStackSet",
"cloudfront:CreateCloudFrontOriginAccessIdentity",
"cloudfront:CreateDistribution",
"cloudfront:DeleteCloudFrontOriginAccessIdentity",
"cloudfront:DeleteDistribution",
"cloudfront:GetCloudFrontOriginAccessIdentity",
"cloudfront:GetCloudFrontOriginAccessIdentityConfig",
"cloudfront:GetDistribution",
"cloudfront:GetDistributionConfig",
"cloudfront:TagResource",
"cloudfront:UntagResource",
"cloudfront:UpdateCloudFrontOriginAccessIdentity",
"cloudfront:UpdateDistribution",
"cognito-identity:CreateIdentityPool",
"cognito-identity:DeleteIdentityPool",
"cognito-identity:DescribeIdentity",
"cognito-identity:DescribeIdentityPool",
"cognito-identity:SetIdentityPoolRoles",
"cognito-identity:UpdateIdentityPool",
"cognito-idp:CreateUserPool",
"cognito-idp:CreateUserPoolClient",
"cognito-idp:DeleteUserPool",
"cognito-idp:DeleteUserPoolClient",
"cognito-idp:DescribeUserPool",
"cognito-idp:UpdateUserPool",
"cognito-idp:UpdateUserPoolClient",
"dynamodb:CreateTable",
"dynamodb:DeleteItem",
"dynamodb:DeleteTable",
"dynamodb:DescribeTable",
"dynamodb:PutItem",
"dynamodb:UpdateItem",
"dynamodb:UpdateTable",
"iam:CreateRole",
"iam:DeleteRole",
"iam:DeleteRolePolicy",
"iam:GetRole",
"iam:GetUser",
"iam:PassRole",
"iam:PutRolePolicy",
"iam:UpdateRole",
"lambda:AddPermission",
"lambda:CreateFunction",
"lambda:DeleteFunction",
"lambda:GetFunction",
"lambda:GetFunctionConfiguration",
"lambda:InvokeAsync",
"lambda:InvokeFunction",
"lambda:RemovePermission",
"lambda:UpdateFunctionCode",
"lambda:UpdateFunctionConfiguration",
"s3:*",
"amplify:*"
],
"Resource": "*"
}
]
}
IAM Roles & MFA
You can optionally configure the Amplify CLI to assume an IAM role by defining a profile for the role in the shared ~/.aws/config file. This is similar to how the AWS CLI functions, including short term credentials. This can be useful when you have multiple developers using one or more AWS accounts, including team workflows where you want to restrict the category updates they might be permitted to make.
When prompted during the execution of amplify init or the amplify configure project command, you will select a configured profile for the role, and the Amplify CLI will handle the logic to retrieve, cache and refresh the temp credentials. If Multi-Factor Authentication (MFA) is enabled, the CLI will prompt you to enter the MFA token code when it needs to retrieve or refresh temporary credentials.
The Amplify CLI has its own mechanism of caching temporary credentials, it does NOT use the same cache of the AWS CLI. The temporary credentials are cached at ~/.amplify/awscloudformation/cache.json. You can remove all cached credentials by removing this file.
If you only want to remove the cached temp credentials associated with a particular project, execute amplify awscloudformation reset-cache or it’s alias amplify aws reset-cache in the project.
Step by step guide to create and assume an IAM role
The following is a step by step guide on how to create an IAM role and make it available for the Amplify CLI.
The setup has three parts, we will use an example to demonstrate this capability.
Assume Biz Corp has decided to hire Dev Corp to develop its inventory management web portal, and Dev Corp is using the Amplify CLI to speed up the development process.
Part #1: Set up the role (Biz Corp)
- Sign in to the AWS Management Console and open the IAM console.
- In the navigation pane of the console, choose
Rolesand then chooseCreate role. - Choose the
Another AWS accountrole type. - For Account ID, type Dev Corp’s AWS account ID (the account ID of the entity you want to grant access to your AWS resources).
- Although optional, it is recommended to select
Require external IDand enter the external id given to you by Dev Corp. (click here for more details on external IDs). - If you want to restrict the role to users who sign in with multi-factor authentication (MFA), select
Require MFA(click here for more details on MFA). - Choose
Next: Permissions. - Select permissions policies that you want the developers from Dev Corp to have when the role is assumed.
Note: You MUST grant the role permissions to perform CloudFormation actions and create associated resources (depending on the categories you use in your project) such as:
- Cognito User and Identity Pools
- S3 buckets
- DynamoDB tables
- AppSync APIs
- API Gateway APIs
- Pinpoint endpoints
- Cloudfront distributions
- IAM Roles
- Lambda functions
- Lex bots
- Choose
Next: Tagging, attach tags if you want (optional). - Choose
Next: Review, type a name for your role, and optionally add the role description. - Enter the required fields such as the “Role name”.
- Choose
Create role. - Give the Role Arn to Dev Corp.
Part #2: Set up the user to assume the role (Dev Corp)
2.1 Create a policy that has permission to assume the role created above by Biz corp.
- Get the Role Arn from Biz Corp.
- Sign in to the AWS Management Console and open the IAM console. (Assuming Dev corp has a separate AWS account).
- In the navigation pane of the console, choose
Policiesand then chooseCreate policy. - Select the ‘JSON’ tab and paste the following contents in the pane, replacing
<biz_corp_rol_arn>with the value previously noted.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "<biz_corp_rol_arn>" } ] } - Choose
Review policy. - Type in the policy Name, and optionally add the policy description.
- Choose
Create policy.
2.2 Attach the policy to the user
- Sign in to the AWS Management Console and open the IAM console.
- In the navigation pane of the console, choose
Usersand then chooseAdd user. - Type the
User namefor the new user. - Select Programmatic access for
Access type. - Choose
Next: Permissions. - On the Set Permissions Page, select
Attach existing policies directly. - Select the policy created in 2.1.
- Choose
Next: Tagging, attach tags if you wish (optional). - Choose
Next: Review. - Choose
Create User. - Click
Download .csvto download a copy of the credentials. You can, optionally, copy paste the Access Key ID and Secret Access Key and store it in a safe location. These credentials would be used in a later section.
2.3 Assign MFA device (Optional)
This must be set up if the Biz Corp selected to Require MFA when creating the role. This needs to be set up by Dev Corp users and in their respective AWS account.
We are using a virtual MFA device, such as the Google Authenticator app, in this example.
- Sign in to the AWS Management Console and open the IAM console.
- In the navigation pane of the console, choose
Usersand select the user created above in 2.2. - Select the
Security Credentialstab. - Next to the
Assigned MFA devicelabel, choose theManageoption. - In the Manage MFA Device wizard, choose
Virtual MFA device, and then chooseContinue. - Choose
Show QR codeif the MFA app supports QR code, and scan the QR code from your virtual device(Google Authenticator app in our case), if not, chooseShow secret keyand type it into the MFA app. - In the MFA code 1 box, type the one-time password that currently appears in the virtual MFA device. Wait for the device to generate a new one-time password. Then type the second one-time password into the MFA code 2 box. Then choose Assign MFA.
- Copy the MFA device arn next to
Assigned MFA device, which will be used in part 3.
Part #3: Set up the local development environment (Dev Corp)
- On the local development system, create the following two files if they do not exist.
~/.aws/config
~/.aws/credentials - Insert the following contents into the
~/.aws/configfile:
[profile bizcorprole]
role_arn=<role_arn_from_part#1>
source_profile=devcorpuser
mfa_serial=<mfa_serial_from_part_2.3---optional>
external_id=<external_id_as_mentioned_in_part#1--optional>
region=us-east-1
[profile devcorpuser]
region=us-east-1
mfa_serial and external_id are optional, leave them out if they are not configured.
- Insert the following contents into the
~/.aws/credentialsfile:[devcorpuser] aws_access_key_id=<key_id_from_part_2.2> aws_secret_access_key=<secret_access_key_from_part_2.2>Now, when Dev Corp is trying to initialize an Amplify Project, the user can select the
bizcorproleprofile configured above, and based on the authentication method set up the user would be prompted with corresponding questions such as MFA codes. After this, the user would be able to successfully deploy/manage AWS resources in Biz corps account (based on the access policies set by the Biz corp).
You can take a look at AWS IAM and the AWS CLI documentation for more details on IAM role and its usage.
Mocking and Testing
It is highly recommended that you complete the Getting Started section of Amplify setup before using local mocking.
In order to quickly test and debug without pushing all changes in your project to the cloud, Amplify supports Local Mocking and Testing for certain categories including API (AWS AppSync), Storage (Amazon DynamoDB and Amazon S3), and Functions (AWS Lambda). This includes using directives from the GraphQL Transformer, editing & debug resolvers, hot reloading, JWT mocking of authorization checks, and even performing S3 operations such as uploading and downloading content.
Java is required on your development workstation to use Local Mocking in Amplify
Blog walk-through with sample app.
API mocking setup
After running amplify init you can immediately add a GraphQL API and begin mocking without first pushing to the cloud. REST APIs are not yet supported. For example:
$ amplify init
$ amplify add api #select GraphQL, use API Key
$ amplify mock api
When you run amplify mock api the codegen process will run and create any required GraphQL assets such as queries, mutations, and subscriptions as well as TypeScript or Swift classes for your app. Android requires a build step for Gradle to create required classes after the codegen process completes, as well as an extra configuration in your AndroidManifest.xml.
If you do not wish to test your app locally, you can still use the local GraphQL console as well as edit, debug, and test your VTL resolvers locally against the mock endpoint.
When adding a schema use an API Key at first to ensure everything works, though you can authenticate against a Cognito User Pool and the local testing server will honor the JWT tokens. You can also mock the JWT tokens in the local console (outlined below), however in that case you will need to do an amplify push first to create the User Pool.
When defining a schema you can use directives from the GraphQL Transformer in local testing as well as local code generation from the schema for types. The following directives are currently supported in local testing:
Note that @searchable is not supported at this time.
Storage mocking setup
For S3 storage mocking, after running amplify init you must first run through amplify add auth, either explicitly or implicitly if adding storage first, and then run an amplify push. This is because mocking storage in client libraries requires credentials for initial setup. Note however that S3 authorization rules, such as those placed on a bucket policy, are not checked by local mocking at this time.
Once you have done an initial push you can run the mock server and hit the local endpoint:
$ amplify init
$ amplify add storage #This will prompt you to add auth
$ amplify push
$ amplify mock storage
To use an iOS application with the local S3 endpoint you will need to modify your Info.plist file. To use an Android application with the local S3 endpoint you will need an extra configuration in your AndroidManifest.xml.
For DynamoDB storage, setup is automatically done when creating a GraphQL API with no action is needed on your part. Resources for the mocked data, such as the DynamoDB Local database or objects uploaded using the local S3 endpoint, inside your project under ./amplify/mock-data.
Function mocking setup
For Lambda function mocking, after running amplify init you can add a function to your project with amplify add function and either mock invoke it directly, or use the @function directive as part of your GraphQL schema to mock the invocation as part of your API.
To invoke the function with the local mock:
$ amplify init
$ amplify add function ## Follow prompts
$ amplify mock function <function_name>
This will take you through a few questions, such as the entry point for your Lambda function and sample event context to pass. The defaults are index.js and event.json.
Note that you will need to run yarn or npm install first if your Lambda function has any external dependencies (<project-dir>/amplify/backend/function/<function-name>/src). Only Node.js functions are supported at this time.
Function mocking with GraphQL
Alternatively, you can add a Lambda function and attach it as a GraphQL resolver with the @function directive. To do this first add a function to your project:
$ amplify init ## specify environment
$ amplify add function
Once the function is added, you can attach it to a field in your GraphQL schema. You will need to append -${env} to the function name in your schema when using the @function directive to denote the environment being used. For example if you ran amplify add function and used the name quoteOfTheDay for your function, and then ran amplify add api, your schema might have a query that looks like the below:
type Query {
getQuote: String @function(name: "quoteOfTheDay-${env}")
}
Then when you run amplify mock the local GraphQL endpoint will invoke this function when running a GraphQL query such as:
query {
getQuote
}
Config files
When performing operations against the local mock endpoint, the Amplify CLI will automatically update your aws-exports.js and awsconfiguration.json with the local endpoints, fake values where necessary (e.g. fake API key), and disable SSL with an explicit value (DangerouslyConnectToHTTPEndpointForTesting) to indicate the functionality is only for local mocking and testing. This happens automatically when you run amplify mock and the server is running. Once you stop the mock server the config files are updated with the correct cloud endpoints for your project and DangerouslyConnectToHTTPEndpointForTesting is removed from the config file.
aws-exports.js example
const awsmobile = {
"aws_project_region": "us-east-1",
"aws_appsync_graphqlEndpoint": "http://localhost:20002/graphql",
"aws_appsync_region": "us-east-1",
"aws_appsync_authenticationType": "AMAZON_COGNITO_USER_POOLS",
"aws_appsync_apiKey": "da2-fakeApiId123456",
"aws_appsync_dangerously_connect_to_http_endpoint_for_testing": true,
"aws_cognito_identity_pool_id": "us-east-1:270445b2-cc92-4d46-a937-e41e49bdb892",
"aws_cognito_region": "us-east-1",
"aws_user_pools_id": "us-east-1_excPT39ZN",
"aws_user_pools_web_client_id": "4a950rsq08d2gi68ogdt7sjqub",
"oauth": {},
"aws_user_files_s3_bucket": "local-testing-app-2fbf0a32d1896419b88f004c2755d084c-dev",
"aws_user_files_s3_bucket_region": "us-east-1",
"aws_user_files_s3_dangerously_connect_to_http_endpoint_for_testing": true
};
awsconfiguration.json example
"AppSync": {
"Default": {
"ApiUrl": "http://localhost:20002/graphql",
"Region": "us-east-1",
"AuthMode": "AMAZON_COGNITO_USER_POOLS",
"ClientDatabasePrefix": "deddd_AMAZON_COGNITO_USER_POOLS",
"DangerouslyConnectToHTTPEndpointForTesting": true
}
},
"S3TransferUtility": {
"Default": {
"Bucket": "local-testing-app-2fbf0a32d1896419b88f004c2755d084c-dev",
"Region": "us-east-1",
"DangerouslyConnectToHTTPEndpointForTesting": true
}
}
iOS config
When running against the local mock S3 server with iOS you must update your Info.plist to not require SSL when on a local network. To enable this set NSAllowsLocalNetworking to YES under NSAppTransportSecurity. This will scope the security exception to only run on localhost domains as outlined in Apple Developer documentation for NSAllowsLocalNetworking.
Android config
When running against the local mock server with Android it is recommended to use additional Build Variants, such as a Debug and Release, to enable cleartext traffic only if the app is running on your local network. This will help ensure that you do not allow unsecured HTTP traffic in your Release Build Variant.
For example, in your Android Studio project create /src/debug/AndroidManifest.xml and in this file create a network configuration file reference android:networkSecurityConfig="@xml/network_security_config":
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android">
<application android:networkSecurityConfig="@xml/network_security_config" />
</manifest>
Then create the network configuration file /src/debug/res/xml/network_security_config.xml and restrict to only run on your localhost IP range:
<?xml version="1.0" encoding="utf-8"?>
<network-security-config>
<domain-config cleartextTrafficPermitted="true">
<domain includeSubdomains="true">10.0.2.2</domain>
</domain-config>
</network-security-config>
Then use a Build Variant and run the Debug build and only test this setting with your local mock server. To learn more about this please see the official Android documentation.
Alternatively, if you are running a non-production application and do not want to use multiple Build Variants, you can set android:usesClearTextTraffic="true" in your AndroidManifest.xml as in the code snippet below. This is not a recommended practice. Ensure you remove this once mocking is complete.
<application
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:theme="@style/AppTheme"
android:usesClearTextTraffic="true" >
<!--other code-->
</application>
GraphQL Local Console
To start testing, before starting your JavaScript/Android/iOS application run the following command:
$ amplify mock
Alternatively, you can run amplify mock api to only mock the API category. When prompted, ensure you select YES to automatically generate queries, mutations, and subscriptions if you are building a client application.
Once the server starts it will print a URL. Open this URL in your browser (it should be http://localhost:20002) and the OneGraph GraphQL console will open up in your browser. You can use the explorer on the left to build out a query/mutation or manually type your statements in the main window. Amplify mocking will use DynamoDB Local to persist the records on your system. If you wish, you can view these in Visual Studio code with SQLite Explorer. Follow the instructions in that repo for connecting to local databases.
When your API is configured to use Cognito User Pools, the local console provides a way to change Username, Groups, and email of the bundled JWT token. These values are used by GraphQL transformers Auth directive. Edit them by clicking Auth and saving your changes, then run operations in the console to test your rules.
GraphQL Resolver Debugging
You can edit VTL templates locally to see if they contain errors, including the line numbers causing problems, before pushing to AppSync. With the local API running navigate to ./amplify/backend/api/APINAME/resolvers where APINAME is the logical name that you used when running $amplify add api. You will see a list of resolver templates that the Transformer generated. Modify any of them and save, and they will be immediately loaded into the locally running API service with a message Mapping template change detected. Reloading.. If there is an error you will see something such as the following:
Reloading failed Error: Parse error on line 1:
...son($context.result
----------------------^
If you stop the server locally, for instance to push your changes to the cloud, all of the templates in the ../APINAME/resolvers directory will be removed except for any that you modified. When you subsequently push to the cloud these local changes will be merged with your AppSync API.
Modify schema and test again
As you are developing your app, you can always modify the GraphQL schema which lives in ./amplify/backend/api/APINAME/schema.graphql. You can modify any types using any of the supported directives and save this file, while the local server is still running. The changes will be detected and if your schema is valid they will be hot reloaded into the local API. If there is an error in the schema an error will be printed to the terminal like so:
Unknown directive "mode".
GraphQL request (1:11)
1: type Todo @mode{
^
2: id: ID!
at GraphQLTransform.transform
Amplify libraries when configured for these categories can use the local mocked endpoints for testing your application. When a mock endpoint is running the CLI will update your aws-exports.js or awsconfiguration.json to use the mock server and once stopped they will be updated to use the cloud endpoint once you have run an amplify push.
Build options
Functions
In some cases, it might be necessary to execute a script before a function is deployed, e.g. to transpile Typescript or ES6 with Babel into a format that is supported by the AWS Lambda’s node runtime. amplify push will look for a script definition in the project root’s package.json with the name amplify:<resource_name> and run it right after npm install is canned in the function resource’s src directory.
Example: Transpiling ES6 code with Babel
Let’s say, a function resource has been created with amplify function add and it is called generateReport. The ES6 source code for this function is located in amplify/backend/function/generateReport/lib and the resource’s src directory only contains the auto-generated package.json for this function. In order to run Babel, you have to add the following script definition and dev dependencies to your project root’s package.json:
{
"scripts": {
"amplify:generateReport": "cd amplify/backend/function/generateReport && babel lib -d src && cd -"
},
"devDependencies": {
"@babel/cli": "^7.5.5",
"@babel/preset-env": "^7.5.5",
}
}
Babel needs to be configured properly so that the transpiled code can be run on AWS Lambda. This can be done by adding a .babelrc file to the resource folder (amplify/backend/function/generateReport/.babelrc in this case):
{
"presets": [
[
"env",
{
"exclude": ["transform-regenerator"],
"targets": {
"node": "10.18"
}
}
]
],
"plugins": [
"transform-async-to-generator",
"transform-exponentiation-operator",
"transform-object-rest-spread"
]
}
Once you run amplify push, the amplify:generateReport script will be executed, either by yarn or by npm depending on the existence of a yarn.lock file in the project root directory.
Architecture
The Amplify CLI has a pluggable architecture. The CLI core provides the pluggable platform, and most of the CLI category functions are implemented as plugins.
Amplify Plugin Platform

Plugins are explicitly managed in the Amplify CLI pluggable platform.
The Amplify CLI Core maintains a plugins.json file to store the plugin management configuration settings and information of all the installed plugins.
The Amplify CLI plugins each contains a amplify-plugin.json file to manifest itself as a valid plugin.
The Amplify CLI Core provides a set of utility commands under amplify plugin for plugin management and to facilitate the development of plugins.
The Amplify CLI Core does not dynamically scan for plugins at the beginning of each command execution. Instead, information about the installed plugins are retrieved from the plugins.json file and only the plugins that are needed for the execution of the command will be loaded.
The plugins.json file is stored at path <os.homedir>/.amplify/plugins.json. Unless you really know what you are doing, you should NOT manually edit this file, otherwise you run the risk of corrupting your local installation of the Amplify CLI.
The plugins.json file will be created or updated in the following situations:
- If the
plugins.jsonfile is not found when the Amplify CLI Core tries to access it, the Amplify CLI Core will create this file and scan the local environment for plugins, and then store the information in the file. - If the last scan time was more than one day (configurable) ago, the Amplify CLI Core will scan again and update the information.
- If inaccuracy is detected, e.g. a specified plugin can not be loaded, the Amplify CLI Core will scan again and update the information.
- After the execution of any of the
amplify plugincommands that could change it, e.g.amplify plugin scan,amplify plugin add/remove.
By default, the CLI core searches for plugins in its parent directory, its local node_modules directory, and the global node_modules directory. Plugins are recognized by the amplify- prefix in the package names.
Plugins communicate with the CLI core and with each other through the project metadata. The CLI core provides the read and write access to the project metadata for the plugins. The project metadata is stored in file amplify/backend/amplify-meta.json in the user project.
Plugin types
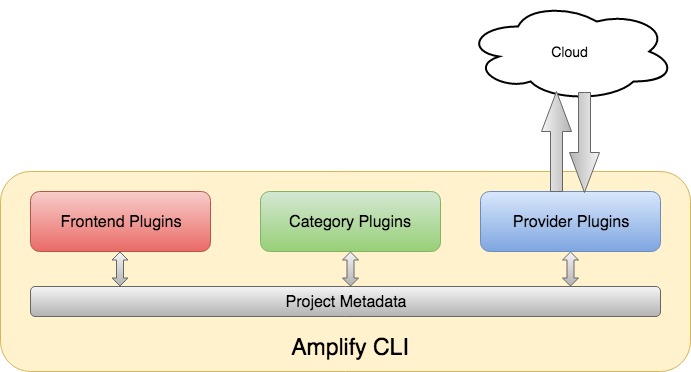
There are four types of plugins
- category
- provider
- frontend
- util
Category plugin
Amplify maintained category plugins are recognized by the amplify-category- prefix in the package name.
A category plugin wraps up the logic to create and manage one category of backend resources in the cloud. It defines the “shape” of the cloud resources based on user (the developer) input, constructs parameters to CRUD cloud resource, and exports relevant cloud resource information to the project metadata.
Categories are managed by AWS and are a functional use case that a client engineer is building as part of their UX, rather than service implementations.
Provider plugin
Amplify maintained provider plugins are recognized by the amplify-provider- prefix in the package name.
A provider plugin abstracts the actual cloud resource provider. It wraps up communication details such as access credentials, api invoke and wait logic, and response data parsing. It also exposes simple interface methods for the category plugins to CRUD cloud resource.
Frontend plugin
Amplify maintained frontend plugins are recognized by the amplify-frontend- prefix in the package name.
A frontend plugin handles a specific type of frontend projects, such as Javascript, Android or iOS projects. Among other things, it provides the following functionalities:
- Formats the cloud resource information and writes it to a file at the right location so it can be recognized and consumed by the frontend project
- Builds and serves the frontend application locally with backend hot-wired to the cloud resources
- Builds and publishes the application (frontend and backend) to its intended users
util plugin
Official util plugins are recognized by the amplify- prefix, without a plugin type decoration in the package name, a util purpose plugin does not manage any backend resources in the cloud, but provides certain CLI commands and/or certain functionalities for the CLI core, and other plugins.
Official category, frontend and provider plugins
- amplify-category-analytics
- amplify-category-api
- amplify-category-auth
- amplify-category-function
- amplify-category-hosting
- amplify-category-interactions
- amplify-category-notifications
- amplify-category-predictions
- amplify-category-storage
- amplify-category-xr
- amplify-codegen
- amplify-frontend-javascript
- amplify-frontend-android
- amplify-frontend-ios
- amplify-provider-awscloudformation
Third party plugin setup
You can add a 3rd party plugin to the Amplify CLI with the following steps:
- If the plugin author named the plugin package according to the naming convention outlined above.
- Run
npm install -g <plugin>and install the plugin to the global node_modules directory. - Run
amplify plugin scanso the Amplify CLI plugin platform will pick up the newly added plugin.
- Run
- If the plugin author did NOT named the plugin package according to the naming convention outlined above.
- Run
npm install -g <plugin>and install the plugin to the global node_modules directory. - Run
amplify plugin addand provide the path to the plugin to explicitly add the plugin package into the Amplify CLI plugin platform.
- Run
Click here for more details on how to author new plugins.
AWS CloudFormation
Currently, the only official provider plugin, amplify-provider-awscloudformation, uses the AWS CloudFormation to form and update the backend resources in the AWS for the amplify categories. For more information about AWS CloudFormation, check its user guide: AWS CloudFormation User Guide
How the CLI works
The amplify-provider-awscloudformation uses nested stacks
Amplify CLI Artifacts
Amplify folder structure
The CLI places the following folder structure at the root directory of the project when init is completed successfully:
amplify
.config
#current-cloud-backend
backend
amplify/.config folder
Contains files that store cloud configuration and user settings/preferences
amplify/#current-cloud-backend folder
Contains backend resources specifications in the cloud from the last synchronization, by the amplify push or amplify env pull command. Each plugin stores contents in its own subfolder inside this folder.
amplify/backend folder
It contains the latest local development of the backend resources specifications to be pushed to the cloud. Each plugin stores contents in its own subfolder inside this folder.
Amplify Files
amplify-meta.json file
Both the amplify/backend and amplify/#current-cloud-backend directories contain an amplify-meta.json file. The amplify-meta.json in the backend directory serves as the whiteboard for the CLI core and the plugins to log information for themselves, and to communicate with each other.
The CLI core provides read and write access to the file for the plugins. Core collects the selected providers’ outputs after init and logs them under the “providers” object, e.g. the awscloudformation provider outputs the information of the root stack, the deployment S3 bucket, and the authorized/unauthorized IAM roles, and they are logged under the providers.awscloudformation object. Each category plugin logs information under its own name.
Because one category might create multiple services within one project (e.g. the interactions category can create multiple bots), the category metadata generally follows a two-level structure like the following:
{
<category>: {
<service1>: {
//service1 metadata
},
<service2>: {
//service2 metadata
}
}
}
The metadata for each service is first logged into the meta file after the amplify <category> add command is executed, containing some general information that indicates one service of the category has been added locally.
Then, on the successful execution of the amplify push command, the output object will be added/updated in the service’s metadata with information that describes the actual cloud resources that have been created or updated.
aws-exports.js file
This file is generated only for JavaScript projects.
It contains the consolidated outputs from all the categories and is placed under the src directory that the user (the developer) specified during the init process. It is updated after each successful execution of the amplify push command, that has created or updated the cloud resources.
This file is consumed by the Amplify JavaScript library for configuration. It contains information which is non-sensitive and only required for external, unauthenticated actions from clients (such as user registration or sign-in flows in the case of Auth) or for constructing appropriate endpoint URLs after authorization has taken place. Please see the following more detailed explanations:
- Cognito security best practices for web app
- Security / Best Practice for poolData (UserPoolId, ClientId) in a browser JS app
- Are the Cognito User pool id and Client Id sensitive?
awsconfiguration.json file
This file is generated for Android and iOS projects.
It contains the consolidated outputs from all the categories. It is updated after each successful execution of the amplify push command, that has created or updated the cloud resources.
This file is consumed by the iOS and Android native SDKs for configuration. It contains information which is non-sensitive and only required for external, unauthenticated actions from clients (such as user registration or sign-in flows in the case of Auth) or for constructing appropriate endpoint URLs after authorization has taken place. Please see the following more detailed explanations: