

API
The API category provides a solution for making HTTP requests to REST and GraphQL endpoints. It includes a AWS Signature Version 4 signer class which automatically signs all AWS API requests for you as well as methods to use API Keys, Amazon Cognito User Pools, or 3rd party OIDC providers.
Using GraphQL Endpoints
The AWS Amplify API module supports AWS AppSync or any other GraphQL backends.
To learn more about GraphQL, please visit the GraphQL website.
Using AWS AppSync
AWS AppSync helps you build data-driven apps with real-time and offline capabilities. Learn more about AWS AppSync by visiting AWS AppSync Developer Guide.
The Amplify Framework offers two client options for AppSync:
The Amplify GraphQL client is a light weight option if you’re looking for a simple way to leverage GraphQL features and do not need the offline capabilities or caching. If you need those features, please look at Amplify DataStore.
Alternatively the AWS AppSync SDK enables you to integrate your app with the AWS AppSync service and integrates with the Apollo client found here.
You can integrate with AWS AppSync using the following steps:
- Set up the API endpoint and authentication information in the client side configuration.
- Generate TypeScript/JavaScript code from the API schema. (optional)
- Write app code to run queries, mutations and subscriptions.
The Amplify CLI provides support for AppSync that make this process easy. Using the CLI, you can configure an AWS AppSync API, download required client side configuration files, and generate client side code within minutes by running a few simple commands on the command line.
Automated Configuration with CLI
After creating your AWS AppSync API, the following command enables AppSync GraphQL API in your project:
$ amplify add api
Select GraphQL when prompted for service type:
? Please select from one of the below mentioned services (Use arrow keys)
❯ GraphQL
REST
Name your GraphQL endpoint and select the authorization type:
? Please select from one of the below mentioned services GraphQL
? Provide API name: myNotesApi
? Choose an authorization type for the API (Use arrow keys)
❯ API key
Amazon Cognito User Pool
AWS AppSync API keys expire seven days after creation, and using API KEY authentication is only suggested for development. To change the AWS AppSync authorization type after the initial configuration, use the $ amplify update api command and select GraphQL.
When you update your backend with the push command, you can go to AWS AppSync Console and see that a new API is added under the APIs menu item:
$ amplify push
Updating Your GraphQL Schema
When you create a GraphQL backend with the CLI, the schema definition for your backend data structure is saved in one of two places:
- By default, schemas are saved in amplify/backend/api/YOUR-API-NAME/schema.graphql. If the
schema.graphqlfile exists, it will take precedence over option 2. - Optionally, schemas may be saved as a set of
.graphqlfiles stored in the amplify/backend/api/YOUR-API-NAME/schema/ directory. E.g. you might have filesQuery.graphql,User.graphql, andPost.graphql.
Once your API is deployed, updating the schema is easy with the CLI. You can edit the schema file(s) and run amplify push command to update your GraphQL backend.
For example, a sample GraphQL schema will look like this:
type Todo @model {
id: ID!
name: String!
description: String
}
Add a priority field to your Todo type:
type Todo @model {
id: ID!
name: String!
description: String
priority: String
}
Save your schema file and update your GraphQL backend:
$ amplify push
When you run the push command, you will notice that your schema change is automatically detected, and your backend will be updated respectively.
| Category | Resource name | Operation | Provider plugin |
| -------- | --------------- | --------- | ----------------- |
| Api | myNotesApi | Update | awscloudformation |
| Auth | cognito6255949a | No Change | awscloudformation |
When the update is complete, you can see the changes on your backend by visiting AWS AppSync Console.
Using GraphQL Transformers
As you can notice in the sample schema file above, the schema has a @model directive. The @model directive leverages a set of libraries that can help simplify the process of bootstrapping highly scalable, serverless GraphQL APIs on AWS. The @model directive tells the GraphQL Transform that we would like to store Todo objects in an Amazon DynamoDB table and configure CRUD operations for it. When you create or update your backend with push command, the CLI will automatically create and configure a new DynamoDB table that works with your AppSync API. The @model directive is just one of multiple transformers that can be used by annotating your schema.graphql.
The following directives are available to be used when defining your schema:
| Directive | Description |
|---|---|
| @model on Object | Store objects in DynamoDB and configure CRUD resolvers. |
| @auth on Object | Define authorization strategies for your API. |
| @connection on Field | Specify relationships between @model object types. |
| @searchable on Object | Stream data of an @model object type to Amazon Elasticsearch Service. |
| @versioned on Object | Add object versioning and conflict detection to a @model. |
You may also write your own transformers to implement reproducible patterns that you find useful. To learn more about the GraphQL Transform libraries see GraphQL Transform Documentation.
Mocking and Local Testing
Amplify supports running a local mock server for testing your application with AWS AppSync, including debugging of resolvers, before pushing to the cloud. Please see the CLI Toolchain documentation for more details.
Generate client types from a GraphQL schema
When working with GraphQL data it is useful to import types from your schema for type safety. You can do this with the Amplify CLI’s automated code generation feature. The CLI automatically downloads GraphQL Introspection Schemas from the defined GraphQL endpoint and generates TypeScript or Flow classes for you. Every time you push your GraphQL API, the CLI will provide you the option to generate types and statements.
If you want to generate your GraphQL statements and types, run:
$ amplify codegen
A TypeScript or Flow type definition file will be generated in your target folder.
Using the Configuration File in Your Code
Import your auto-generated aws-exports.js file to configure your app to work with your AWS AppSync GraphQL backend:
import awsconfig from './aws-exports';
Amplify.configure(awsconfig);
Manual Configuration
As an alternative to automatic configuration, you can manually enter AWS AppSync configuration parameters in your app. Authentication type options are API_KEY, AWS_IAM, AMAZON_COGNITO_USER_POOLS and OPENID_CONNECT.
Using API_KEY
const myAppConfig = {
// ...
'aws_appsync_graphqlEndpoint': 'https://xxxxxx.appsync-api.us-east-1.amazonaws.com/graphql',
'aws_appsync_region': 'us-east-1',
'aws_appsync_authenticationType': 'API_KEY',
'aws_appsync_apiKey': 'da2-xxxxxxxxxxxxxxxxxxxxxxxxxx',
// ...
}
Amplify.configure(myAppConfig);
Using AWS_IAM
const myAppConfig = {
// ...
'aws_appsync_graphqlEndpoint': 'https://xxxxxx.appsync-api.us-east-1.amazonaws.com/graphql',
'aws_appsync_region': 'us-east-1',
'aws_appsync_authenticationType': 'AWS_IAM',
// ...
}
Amplify.configure(myAppConfig);
Using AMAZON_COGNITO_USER_POOLS
const myAppConfig = {
// ...
'aws_appsync_graphqlEndpoint': 'https://xxxxxx.appsync-api.us-east-1.amazonaws.com/graphql',
'aws_appsync_region': 'us-east-1',
'aws_appsync_authenticationType': 'AMAZON_COGNITO_USER_POOLS', // You have configured Auth with Amazon Cognito User Pool ID and Web Client Id
// ...
}
Amplify.configure(myAppConfig);
Using OPENID_CONNECT
const myAppConfig = {
// ...
'aws_appsync_graphqlEndpoint': 'https://xxxxxx.appsync-api.us-east-1.amazonaws.com/graphql',
'aws_appsync_region': 'us-east-1',
'aws_appsync_authenticationType': 'OPENID_CONNECT', // Before calling API.graphql(...) is required to do Auth.federatedSignIn(...) check authentication guide for details.
// ...
}
Amplify.configure(myAppConfig);
Using a GraphQL Server
To access a GraphQL API with your app, you need to configure the endpoint URL in your app’s configuration. Add the following line to your setup:
import Amplify, { API } from 'aws-amplify';
import awsconfig from './aws-exports';
// Considering you have an existing aws-exports.js configuration file
Amplify.configure(awsconfig);
// Configure a custom GraphQL endpoint
Amplify.configure({
API: {
graphql_endpoint: 'https:/www.example.com/my-graphql-endpoint'
}
});
Set Custom Request Headers for GraphQL
When working with a GraphQL endpoint, you may need to set request headers for authorization purposes. This is done by passing a graphql_headers function into the configuration:
Amplify.configure({
API: {
graphql_headers: async () => ({
'My-Custom-Header': 'my value'
})
}
});
Signing Request with IAM
AWS Amplify provides the ability to sign requests automatically with AWS Identity Access Management (IAM) for GraphQL requests that are processed through AWS API Gateway. Add the graphql_endpoint_iam_region parameter to your GraphQL configuration statement to enable signing:
Amplify.configure({
API: {
graphql_endpoint: 'https://www.example.com/my-graphql-endpoint',
graphql_endpoint_iam_region: 'my_graphql_apigateway_region'
}
});
Amplify GraphQL Client
The API category provides a GraphQL client for working with queries, mutations, and subscriptions. This client does not support offline programming.
Query Declarations
The Amplify CLI codegen automatically generates all possible GraphQL statements (queries, mutations and subscriptions) and for JavaScript applications saves it in src/graphql folder
import * as queries from './graphql/queries';
import * as mutations from './graphql/mutations';
import * as subscriptions from './graphql/subscriptions';
Simple Query
Running a GraphQL query is simple. Import the generated query and execute it with API.graphql:
import Amplify, { API, graphqlOperation } from 'aws-amplify';
import * as queries from './graphql/queries';
// Simple query
const allTodos = await API.graphql(graphqlOperation(queries.listTodos));
console.log(allTodos);
// Query using a parameter
const oneTodo = await API.graphql(graphqlOperation(queries.getTodo, { id: 'some id' }));
console.log(oneTodo);
Mutations
Mutations are used to create or update data with GraphQL. A sample mutation query to create a new Todo looks like this:
import Amplify, { API, graphqlOperation } from "aws-amplify";
import * as mutations from './graphql/mutations';
// Mutation
const todoDetails = {
name: 'Todo 1',
description: 'Learn AWS AppSync'
};
const newTodo = await API.graphql(graphqlOperation(mutations.createTodo, {input: todoDetails}));
console.log(newTodo);
Subscriptions
Subscriptions is a GraphQL feature allowing the server to send data to its clients when a specific event happens. You can enable real-time data integration in your app with a subscription.
import Amplify, { API, graphqlOperation } from 'aws-amplify';
import * as subscriptions from './graphql/subscriptions';
// Subscribe to creation of Todo
const subscription = API.graphql(
graphqlOperation(subscriptions.onCreateTodo)
).subscribe({
next: (todoData) => console.log(todoData)
});
// Stop receiving data updates from the subscription
subscription.unsubscribe();
When using AWS AppSync subscriptions, be sure that your AppSync configuration is at the root of the configuration object, instead of being under API:
Amplify.configure({
Auth: {
identityPoolId: 'xxx',
region: 'xxx' ,
cookieStorage: {
domain: 'xxx',
path: 'xxx',
secure: true
}
},
aws_appsync_graphqlEndpoint: 'xxxx',
aws_appsync_region: 'xxxx',
aws_appsync_authenticationType: 'xxxx',
aws_appsync_apiKey: 'xxxx'
});
AWS AppSync Multi-Auth
AWS AppSync can support multiple authorization modes on a single API. In order to use this feature with the Amplify Graphql Client the API.graphql({...}) function would accept an optional parameter called authMode, its value will be one of the supported auth modes:
API_KEYAWS_IAMOPENID_CONNECTAMAZON_COGNITO_USER_POOLS
This is an example of using AWS_IAM as an authorization mode:
// Creating a post is restricted to IAM
const createdTodo = await API.graphql({
query: queries.createTodo,
variables: {input: todoDetails},
authMode: 'AWS_IAM'
});
Note: Previous examples uses graphqlOperation function. That function only creates an object with two attributes query and variables. In order to use authMode you need to pass this object as is mentioned on the previous example.
React Components
The API category provides React components for working with GraphQL data using the Amplify GraphQL client.
Connect
The <Connect/> component is used to execute a GraphQL query or mutation. You can execute GraphQL queries by passing your queries in query or mutation attributes:
import React, { Component } from 'react';
import Amplify, { graphqlOperation } from "aws-amplify";
import { Connect } from "aws-amplify-react";
import * as queries from './graphql/queries';
import * as subscriptions from './graphql/subscriptions';
class App extends Component {
render() {
const ListView = ({ todos }) => (
<div>
<h3>All Todos</h3>
<ul>
{todos.map(todo => <li key={todo.id}>{todo.name} ({todo.id})</li>)}
</ul>
</div>
);
return (
<Connect query={graphqlOperation(queries.listTodos)}>
{({ data: { listTodos }, loading, errors }) => {
if (errors) return (<h3>Error</h3>);
if (loading || !listTodos) return (<h3>Loading...</h3>);
return (<ListView todos={listTodos.items} /> );
}}
</Connect>
)
}
}
export default App;
Also, you can use the subscription and onSubscriptionMsg attributes to enable subscriptions:
<Connect
query={graphqlOperation(queries.listTodos)}
subscription={graphqlOperation(subscriptions.onCreateTodo)}
onSubscriptionMsg={(prev, { onCreateTodo }) => {
console.log ( onCreateTodo );
return prev;
}}
>
{({ data: { listTodos }, loading, error }) => {
if (error) return (<h3>Error</h3>);
if (loading || !listTodos) return (<h3>Loading...</h3>);
return (<ListView todos={listTodos ? listTodos.items : []} />);
}}
</Connect>
For mutations, a mutation function needs to be provided with the Connect component. A mutation returns a promise that resolves with the result of the GraphQL mutation.
import React, { Component } from 'react';
import * as mutations from './graphql/mutations';
import * as queries from './graphql/queries';
import * as subscriptions from './graphql/subscriptions';
class AddTodo extends Component {
constructor(props) {
super(props);
this.submit = this.submit.bind(this);
this.state = {
name: '',
description: '',
};
}
handleChange(name, event) {
this.setState({ [name]: event.target.value });
}
async submit() {
const { onCreate } = this.props;
const input = {
name: this.state.name,
description: this.state.description
}
console.log(input);
try {
await onCreate({input})
} catch (err) {
console.error(err);
}
}
render(){
return (
<div>
<input
name="name"
placeholder="name"
onChange={(event) => { this.handleChange('name', event)}}
/>
<input
name="description"
placeholder="description"
onChange={(event) => { this.handleChange('description', event)}}
/>
<button onClick={this.submit}>
Add
</button>
</div>
);
}
}
class App extends Component {
render() {
const ListView = ({ todos }) => (
<div>
<h3>All Todos</h3>
<ul>
{todos.map(todo => <li key={todo.id}>{todo.name}</li>)}
</ul>
</div>
)
return (
<div className="App">
<Connect mutation={graphqlOperation(mutations.createTodo)}>
{({mutation}) => (
<AddTodo onCreate={mutation} />
)}
</Connect>
<Connect query={graphqlOperation(queries.listTodos)}
subscription={graphqlOperation(subscriptions.onCreateTodo)}
onSubscriptionMsg={(prev, {onCreateTodo}) => {
console.log('Subscription data:', onCreateTodo)
return prev;
}
}>
{({ data: { listTodos }, loading, error }) => {
if (error) return <h3>Error</h3>;
if (loading || !listTodos) return <h3>Loading...</h3>;
return (<ListView todos={listTodos.items} />);
}}
</Connect>
</div>
);
}
}
AWS AppSync SDK
The following documentation outlines how to use the Apollo client with AWS AppSync and important client APIs to understand. For sample code to use in your JavaScript framework such as React, Vue, etc. or to open issues with the SDK please see the AppSync Apollo client SDK GitHub repository.
Configuration
The AWS SDKs support configuration through a centralized file called aws-exports.js that defines your AWS regions and service endpoints. You obtain this file in one of two ways, depending on whether you are creating your AppSync API in the AppSync console or using the Amplify CLI.
-
If you are creating your API in the console, navigate to the
Getting Startedpage, and follow the steps in theIntegrate with your appsection. Theaws-exports.jsfile you download is already populated for your specific API. Place the file in thesrcdirectory of your JavaScript project. -
If you are creating your API with the Amplify CLI (using
amplify add api), theaws-exports.jsfile is automatically downloaded and updated each time you runamplify pushto update your cloud resources. The file is placed in thesrcdirectory that you choose when setting up your JavaScript project.
Code Generation
To execute GraphQL operations in JavaScript you need to have GraphQL statements (for example, queries, mutations, or subscriptions) to send over the network to the server. You can optionally run a code generation process to do this for you. The Amplify CLI toolchain makes this easy by automatically pulling down your schema and generating default GraphQL queries, mutations, and subscriptions. If your client requirements change, you can alter these GraphQL statements and your JavaScript project will automatically pick them up. You can also generate TypeScript definitions with the CLI and regenerate your types.
AppSync APIs Created in the Console
After installing the Amplify CLI open a terminal, go to your JavaScript project root, and then run the following:
amplify init
amplify add codegen --apiId XXXXXX
The XXXXXX is the unique AppSync API identifier that you can find in the console in the root of your API’s integration page. When you run this command you can accept the defaults, which create a ./src/graphql folder structure with your statements.
AppSync APIs Created Using the CLI
Navigate in your terminal to a JavaScript project directory and run the following:
$amplify init ## Select JavaScript as your platform
$amplify add api ## Select GraphQL, API key, "Single object with fields Todo application"
Select GraphQL when prompted for service type:
? Please select from one of the below mentioned services (Use arrow keys)
❯ GraphQL
REST
The add api flow above will ask you some questions, such as if you already have an annotated GraphQL schema. If this is your first time using the CLI select No and let it guide you through the default project “Single object with fields (e.g., “Todo” with ID, name, description)” as it will be used in the code examples below. Later on, you can always change it.
Name your GraphQL endpoint and select authorization type:
? Please select from one of the below mentioned services GraphQL
? Provide API name: myTodosApi
? Choose an authorization type for the API (Use arrow keys)
❯ API key
Amazon Cognito User Pool
AWS AppSync API keys expire seven days after creation, and using API KEY authentication is only suggested for development. To change AWS AppSync authorization type after the initial configuration, use the $ amplify update api command and select GraphQL.
When you update your backend with push command, you can go to AWS AppSync Console and see that a new API is added under APIs menu item:
$ amplify push
The amplify push process will prompt you to enter the codegen process and walk through configuration options. Accept the defaults and it will create a ./src/graphql folder structure with your documents. You also will have an aws-exports.js file that the AppSync client will use for initialization. At any time you can open the AWS console for your new API directly by running the following command:
$ amplify console api
> GraphQL ##Select GraphQL
This will open the AWS AppSync console for you to run Queries, Mutations, or Subscriptions at the server and see the changes in your client app.
Dependencies
To use AppSync in your JavaScript project, add in the following dependencies:
npm install aws-appsync graphql-tag
# or
yarn add aws-appsync graphql-tag
Client Initialization
In your app’s entry point, import the AWS AppSync Client and instantiate it.
import gql from 'graphql-tag';
import AWSAppSyncClient, { AUTH_TYPE } from 'aws-appsync';
import awsconfig from './aws-exports';
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: AUTH_TYPE.API_KEY, // or type: awsconfig.aws_appsync_authenticationType,
apiKey: awsconfig.aws_appsync_apiKey,
}
});
Run a Query
Now that the client is configured, you can run a GraphQL query. The syntax is client.query({ query: QUERY}) which returns a Promise you can optionally await on. The QUERY is a GraphQL document you can write yourself or use the statements which amplify codegen created automatically. For example, if you have a ListTodos query, your code will look like the following:
import { listTodos } from './graphql/queries';
client.query({
query: gql(listTodos)
}).then(({ data: { listTodos } }) => {
console.log(listTodos.items);
});
If you want to change the fetchPolicy to something like cache-only and not retrieve data over the network, you need to wait for the cache to be hydrated (instantiate an in-memory object from storage for the Apollo cache to use).
import { listTodos } from './graphql/queries';
(async () => {
await client.hydrated();
const result = await client.query({
query: gql(listTodos),
fetchPolicy: 'cache-only',
});
console.log(result.data.listTodos.items);
})();
We recommend leaving the default of fetchPolicy: 'cache-and-network for usage with AppSync.
Run a Mutation
To add data you need to run a GraphQL mutation. The syntax is client.mutate({ mutation:MUTATION, variables: vars}) which like a query returns a Promise. The MUTATION is a GraphQL document you can write yourself use use the statements which amplify codegen created automatically. variables are an optional object if the mutation requires arguments. For example, if you have a createTodo mutation, your code will look like the following (using async/await in this example):
import { createTodo } from './graphql/mutations';
(async () => {
const result = await client.mutate({
mutation: gql(createTodo),
variables: {
input: {
name: 'Use AppSync',
description: 'Realtime and Offline',
}
}
});
console.log(result.data.createTodo);
})();
Subscribe to Data
Finally, it’s time to set up a subscription to real-time data. The syntax is client.subscribe({ query: SUBSCRIPTION }) which returns an Observable that you can subscribe to with .subscribe() as well as .unsubscribe() when the data is no longer necessary in your application. For example, if you have a onCreateTodo subscription, your code might look like the following:
import { onCreateTodo } from './graphql/subscriptions';
let subscription;
(async () => {
subscription = client.subscribe({ query: gql(onCreateTodo) }).subscribe({
next: data => {
console.log(data.data.onCreateTodo);
},
error: error => {
console.warn(error);
}
});
})();
// Unsubscribe after 10 secs
setTimeout(() => {
subscription.unsubscribe();
}, 10000);
Note that since client.subscribe returns an Observable, you can use filter, map, forEach and other stream related functions. When you subscribe, you’ll get back a subscription object you can use to unsubscribe.
Subscriptions can also take input types like mutations, in which case they will be subscribing to particular events based on the input. To learn more about subscription arguments, see Real-Time data.
Client Architecture
The AppSync client supports offline scenarios with a programing model that provides a “write through cache”. This allows you to both render data in the UI when offline as well as add/update through an “optimistic response”. The below diagram shows how the AppSync client interfaces with the network GraphQL calls, it’s offline mutation queue, the Apollo cache, and your application code.
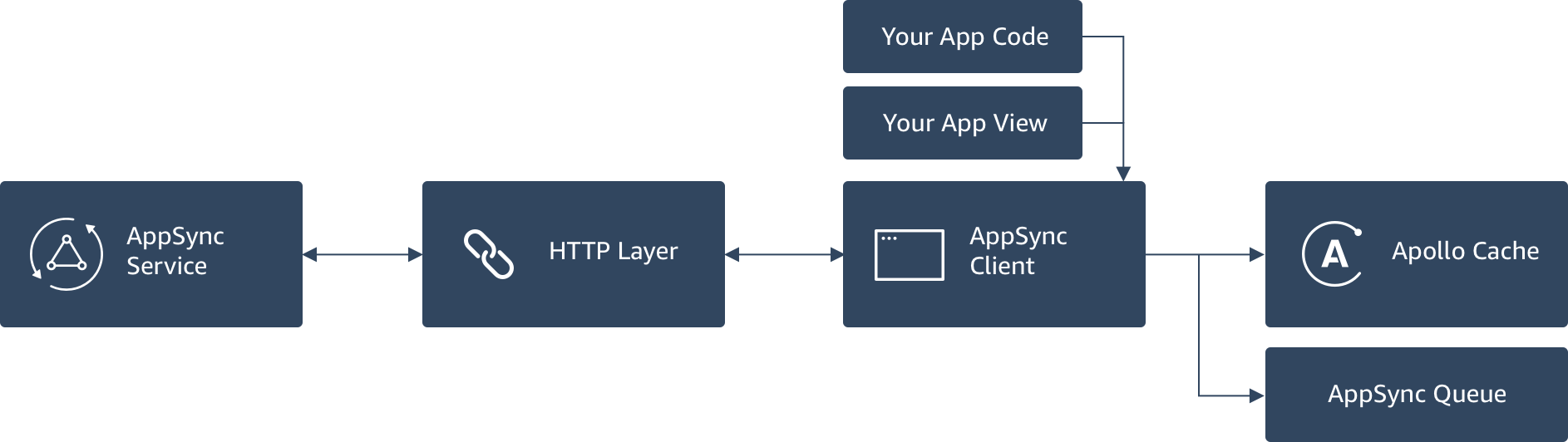
Your application code will interact with the AppSync client to perform GraphQL queries, mutations, or subscriptions. The AppSync client automatically performs the correct authorization methods when interfacing with the HTTP layer adding API Keys, tokens, or signing requests depending on how you have configured your setup. When you do a mutation, such as adding a new item (like a blog post) in your app the AppSync client adds this to a local queue (persisted to disk with Local Storage, AsyncStorage, or other mediums depending on your JavaScript platform configuration) when the app is offline. When network connectivity is restored the mutations are sent to AppSync in serial allowing you to process the responses one by one.
Any data returned by a query is automatically written to the Apollo Cache (e.g. “Store”) that is persisted to the configured medium. The cache is structured as a key value store using a reference structure. There is a base “Root Query” where each subsequent query resides and then references their individual item results. You specify the reference key (normally “id”) in your application code. An example of the cache that has stored results from a “listPosts” query and “getPost(id:1)” query is below.
| Key | Value |
| ROOT_QUERY | [ROOT_QUERY.listPosts, ROOT_QUERY.getPost(id:1)] |
| ROOT_QUERY.listPosts | {0, 1, …,N} |
| Post:0 | {author:”Nadia”, content:”ABC”} |
| Post:1 | {author:”Shaggy”, content:”DEF”} |
| … | … |
| Post:N | {author:”Pancho”, content:”XYZ”} |
| ROOT_QUERY.getPost(id:1) | ref: $Post:1 |
Notice that the cache keys are normalized where the getPost(id:1) query references the same element that is part of the listPosts query. This happens automatically in JavaScript applications by using id as a common cache key to uniquely identify the objects. You can choose to change the cache key with the cacheOptions :{ dataIdFromObject } method when creating the AWSAppSyncClient:
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: AUTH_TYPE.API_KEY,
apiKey: awsconfig.aws_appsync_apiKey,
},
cacheOptions: {
dataIdFromObject: (obj) => `${obj.__typename}:${obj.myKey}`
}
});
If you are performing a mutation, you can write an “optimistic response” anytime to this cache even if you are offline. You use the AppSync client to connect by passing in the query to update, reading the items off the cache. This normally returns a single item or list of items, depending on the GraphQL response type of the query to update. At this point you would add to the list, remove, or update it as appropriate and write back the response to the store persisting it to disk. When you reconnect to the network any responses from the service will overwrite the changes as the authoritative response. We’ll give some examples of that in Offline mutations.
Configuration Options
disableOffline: If you don’t need/want offline capabilities, this option skips the creation of a local store to persist the cache and mutations made while offline.
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: AUTH_TYPE.API_KEY,
apiKey: awsconfig.aws_appsync_apiKey,
},
disableOffline: true
});
conflictResolver:
When clients make a mutation, either online or offline, they can send a version number with the payload (named expectedVersion) for AWS AppSync to check before writing to Amazon DynamoDB. A DynamoDB resolver mapping template can be configured to perform conflict resolution in the cloud, which you can learn about in the AppSync Resolver Mapping Template Reference for DynamoDB. If the service determines it needs to reject the mutation, data is sent to the client and you can optionally run a “custom conflict resolvers” to perform client-side conflict resolution.
- mutation: GraphQL statement of a mutation
- mutationName: Optional if a name of a mutation is set on a GraphQL statement
- variables: Input parameters of the mutation
- data: Response from AWS AppSync of actual data in DynamoDB
- retries: Number of times a mutation has been retried
An example below of passing a conflictResolver to the AWSAppSyncClient object:
const conflictResolver = ({ mutation, mutationName, variables, data, retries }) => {
switch (mutationName) {
case 'UpdatePostMutation':
return {
...variables,
expectedVersion: data.version,
};
default:
return false;
}
}
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: AUTH_TYPE.API_KEY,
apiKey: awsconfig.aws_appsync_apiKey,
},
conflictResolver: conflictResolver
});
In the previous example, you could do a logical check on the mutationName. If you return an object with variables for the mutation, this will automatically rerun the mutation with the correct version that AWS AppSync returned.
Note: We recommend doing this only in rare cases. Usually, we recommend that you let the AWS AppSync service define conflict resolution to prevent race conditions from occurring. If you don’t want to retry, simply return "DISCARD".
Offline configuration
When using the AWS AppSync SDK offline capabilities (e.g. disableOffline: false), you can provide configurations in the offlineConfig key:
- Error handling: (
callback) - Custom storage engine (
storage) - A key prefix for the underlying store (
keyPrefix)
Error handling
If a mutation is done while the app was offline, it gets persisted to the platform storage engine. When coming back online, it is sent to the GraphQL endpoint. When a response is returned by the API, the SDK will notify you of the success or error using the callback provided in the offlineConfig parameter as follows:
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: AUTH_TYPE.API_KEY,
apiKey: awsconfig.aws_appsync_apiKey,
},
offlineConfig: {
callback: (err, succ) => {
if(err) {
const { mutation, variables } = err;
console.warn(`ERROR for ${mutation}`, err);
} else {
const { mutation, variables } = succ;
console.info(`SUCCESS for ${mutation}`, succ);
}
},
},
});
NOTE If the app was closed and you re-opened it and there were errors this would be represented in the error callback above. However, if you’re doing a mutation and the app is still online and the server rejects the write, you will need to handle it with a standard try/catch:
(async () => {
const variables = {
input: {
name: 'Use AppSync',
description: 'Realtime and Offline',
}
};
try {
const result = await client.mutate({
mutation: gql(createTodo),
variables: variables
});
} catch (e) {
console.warn('Error sending mutation: ', e);
console.warn(variables); // Do something with the data
}
})();
NOTE The SDK will automatically retry for standard network errors, however access errors or other unrelated errors you will need to handle them yourself.
Custom storage engine
You can use any custom storage engine from the redux-persist supported engines list.
Configuration is done as follows: (localForage shown in the example)
import * as localForage from "localforage";
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: AUTH_TYPE.API_KEY,
apiKey: awsconfig.aws_appsync_apiKey,
},
offlineConfig: {
storage: localForage,
},
});
Key prefix
The AWSAppSyncClient persists its cache data to support offline scenarios. Keys in the persisted cache will be prefixed by the provided keyPrefix.
This prefix is required when offline support is enabled and you want to use more than one client in your app (e.g. by accessing a multi-auth enabled AppSync API)
Offline Mutations
As outlined in the architecture section, all query results are automatically persisted to disk with the AppSync client. For updating data through mutations when offline you will need to use an “optimistic response” by writing directly to the store. This is done by querying the store directly with cache.readQuery({query: someQuery}) to pull the records for a specific query that you wish to update. You can do this manually with update functions or use the buildMutation and buildSubscription built-in helpers that are part of the AppSync SDK (we strongly recommended using these helpers).
You can find the Offline Helpers documentation here.
The update functions can be called two or more times when using an optimisticResponse depending on the number of mutation you have in your offline queue and if you are currently offline. This is because the Apollo client will call the function once for the local optimistic write and a second time for the server response. You can read more about this in the Apollo documentation for cache updates. The AppSync client when offline will automatically resolve the promise for the server response and place your mutation in a queue for later processing. When you come back online, each item in the queue will be executed in serial and its corresponding update function will run as well as triggering the optimistic update of the pending items in the queue. This is to ensure that the cache is consistent when rendering the UI. Note that this means that your update functions should be idempotent.
For example, the below code shows how you would update the CreateTodoMutation mutation from earlier by creating a optimisticWrite(CreateTodoInput createTodoInput) helper method that has the same input. This adds an item to the cache by first adding query results to a local array with items.addAll(response.data().listTodos().items()) followed by the individual update using items.add(). You commit the record with client.getStore().write(). This example uses a locally generated unique identifier which might be enough for your app, however if the AppSync response returns a different value for ID (which many times is the case as best practice is generation of IDs at the service layer) then you will need to replace the value locally when a response is received. this can be done in the onResponse() method of the top level mutation callback by again querying the store, removing the item and calling client.getStore().write().
With helper
An example of using the buildMutation helper to add an item to the cache:
import { buildMutation } from 'aws-appsync';
import { listTodos } from './graphql/queries';
import { createTodo, CreateTodoInput } from './graphql/mutations';
(async () => {
const result = await client.mutate(buildMutation(client,
gql(createTodo),
{
inputType: gql(CreateTodoInput),
variables: {
input: {
name: 'Use AppSync',
description: 'Realtime and Offline',
}
}
},
(_variables) => [ gql(listTodos) ],
'Todo'));
console.log(result);
})();
Without helper
An example of writing an update function manually to add an item to the cache:
import { v4 as uuid } from 'uuid';
import { listTodos } from './graphql/queries';
import { createTodo } from './graphql/mutations';
(async () => {
const result = await client.mutate({
mutation: gql(createTodo),
variables: {
input: {
name: 'Use AppSync',
description: 'Realtime and Offline',
}
},
optimisticResponse: () => ({
createTodo: {
__typename: 'Todo', // This type must match the return type of the query below (listTodos)
id: uuid(),
name: 'Use AppSync',
description: 'Realtime and Offline',
}
}),
update: (cache, { data: { createTodo } }) => {
const query = gql(listTodos);
// Read query from cache
const data = cache.readQuery({ query });
// Add newly created item to the cache copy
data.listTodos.items = [
...data.listTodos.items.filter(item => item.id !== createTodo.id),
createTodo
];
//Overwrite the cache with the new results
cache.writeQuery({ query, data });
}
});
console.warn(result);
})();
You might add similar code in your app for updating or deleting items using an optimistic response, it would look largely similar except that you might overwrite or remove an element from the data.listTodos.items array.
Authentication Modes
For client authorization, AppSync supports API Keys, Amazon IAM credentials (we recommend using Amazon Cognito Identity Pools for this option), Amazon Cognito User Pools, and 3rd party OIDC providers. This is inferred from the aws-exports.js when you call .awsConfiguration() on the AWSAppSyncClient builder.
API Key Auth
API Key is the easiest way to set up and prototype your application with AppSync. It’s also a good option if your application is completely public. If your application needs to interact with other AWS services besides AppSync, such as S3, you will need to use IAM credentials provided by Cognito Identity Pools, which also supports “Guest” access. See the authentication section for more details. For manual configuration, add the following snippet to your aws-exports.js file:
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: AUTH_TYPE.API_KEY,
apiKey: awsconfig.aws_appsync_apiKey,
},
});
Cognito User Pools Auth
Amazon Cognito User Pools is the most common service to use with AppSync when adding user Sign-Up and Sign-In to your application. If your application needs to interact with other AWS services besides AppSync, such as S3, you will need to use IAM credentials with Cognito Identity Pools. The Amplify CLI can automatically configure this for you when running amplify add auth and can also automatically federate User Pools with Identity Pools. This allows you to have both User Pool credentials for AppSync and AWS credentials for S3. You can then use the Auth category for automatic credentials refresh as outlined in the authentication section. For manual configuration, add the following snippet to your aws-exports.js file:
import Amplify, { Auth } from 'aws-amplify';
import awsconfig from './aws-exports';
Amplify.configure(awsconfig);
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: AUTH_TYPE.AMAZON_COGNITO_USER_POOLS,
jwtToken: async () => (await Auth.currentSession()).getIdToken().getJwtToken(),
},
});
NOTE In React, you can use amplify’s withAuthenticator:
import { withAuthenticator } from 'aws-amplify-react';
export default withAuthenticator(App);
IAM Auth
When using AWS IAM in a mobile application you should leverage Amazon Cognito Identity Pools. The Amplify CLI will automatically configure this for you when running amplify add auth. You can then use the Auth category for automatic credentials refresh as outlined in the authentication section For manual configuration, add the following snippet to your aws-exports.js file:
import Amplify, { Auth } from 'aws-amplify';
import awsconfig from './aws-exports';
Amplify.configure(awsconfig);
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: AUTH_TYPE.AWS_IAM,
credentials: () => Auth.currentCredentials(),
},
});
NOTE In React, you can use amplify’s withAuthenticator:
import { withAuthenticator } from 'aws-amplify-react';
export default withAuthenticator(App);
OIDC Auth
If you are using a 3rd party OIDC provider you will need to configure it and manage the details of token refreshes yourself. Update the aws-exports.js file and code snippet as follows:
import Amplify, { Auth } from 'aws-amplify';
import awsconfig from './aws-exports';
Amplify.configure(awsconfig);
const getOIDCToken = async () => await 'token'; // Should be an async function that handles token refresh
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: AUTH_TYPE.OPENID_CONNECT,
jwtToken: () => getOIDCToken(),
},
});
Complex objects
Many times you might want to create logical objects that have more complex data, such as images or videos, as part of their structure. For example, you might create a Person type with a profile picture or a Post type that has an associated image. With AWS AppSync, you can model these as GraphQL types, referred to as complex objects. If any of your mutations have a variable with bucket, key, region, mimeType and localUri fields, the SDK uploads the file to Amazon S3 for you.
For a complete working example of this feature, see aws-amplify-graphql on GitHub.
The GraphQL transformer will configure your resolvers to write to DynamoDB and point at S3 objects when using the S3Object type. For example, run the following in an Amplify project:
amplify add auth #Select default configuration
amplify add storage #Select S3 with read/write access
amplify add api #Select Cognito User Pool for authorization type
When prompted, use the following schema:
type Todo @model {
id: ID!
name: String!
description: String!
file: S3Object
}
type S3Object {
bucket: String!
key: String!
region: String!
}
input CreateTodoInput {
id: ID
name: String!
description: String
file: S3ObjectInput # This input type will be generated for you
}
Save and run amplify push to deploy changes.
To use complex objects you need AWS Identity and Access Management credentials for reading and writing to Amazon S3 which amplify add auth configured in the default setting along with a Cognito user pool. These can be separate from the other auth credentials you use in your AWS AppSync client. Credentials for complex objects are set using the complexObjectsCredentials parameter, which you can use with AWS Amplify and the complex objects feature like so:
const client = new AWSAppSyncClient({
url: ENDPOINT,
region: REGION,
auth: { ... }, //Can be User Pools or API Key
complexObjectsCredentials: () => Auth.currentCredentials(),
});
(async () => {
let file;
if (selectedFile) { // selectedFile is the file to be uploaded, typically comes from an <input type="file" />
const { name, type: mimeType } = selectedFile;
const [, , , extension] = /([^.]+)(\.(\w+))?$/.exec(name);
const bucket = aws_config.aws_user_files_s3_bucket;
const region = aws_config.aws_user_files_s3_bucket_region;
const visibility = 'private';
const { identityId } = await Auth.currentCredentials();
const key = `${visibility}/${identityId}/${uuid()}${extension && '.'}${extension}`;
file = {
bucket,
key,
region,
mimeType,
localUri: selectedFile,
};
}
const result = await client.mutate({
mutation: gql(createTodo),
variables: {
input: {
name: 'Upload file',
description: 'Uses complex objects to upload',
file: file,
}
}
});
})();
When you run the above mutation a record will be in a DynamoDB table for your AppSync API as well as the corresponding file in an S3 bucket.
Delta Sync
DeltaSync allows you to perform automatic synchronization with an AWS AppSync GraphQL server. The client will perform reconnection, exponential backoff, and retries when network errors take place for simplified data replication to devices. It does this by taking the results of a GraphQL query and caching it in the local Apollo cache. The DeltaSync API manages writes to the Apollo cache for you, and all rendering in your app (such as from React components, Angular bindings) should be done through a read-only fetch.
In the most basic form, you can use a single query with the API to replicate the state from the backend to the client. This is referred to as a “Base Query” and could be a list operation for a GraphQL type which might correspond to a DynamoDB table. For large tables where the content changes frequently and devices switch between offline and online frequently as well, pulling all changes for every network reconnect can result in poor performance on the client. In these cases you can provide the client API a second query called the “Delta Query” which will be merged into the cache. When you do this the Base Query is run an initial time to hydrate the cache with data, and on each network reconnect the Delta Query is run to just get the changed data. The Base Query is also run on a regular bases as a “catch-up” mechanism. By default this is every 24 hours however you can make it more or less frequent.
By allowing clients to separate the base hydration of the cache using one query and incremental updates in another query, you can move the computation from your client application to the backend. This is substantially more efficient on the clients when regularly switching between online and offline states. This could be implemented in your AWS AppSync backend in different ways such as using a DynamoDB Query on an index along with a conditional expression. You can also leverage Pipeline Resolvers to partition your records to have the delta responses come from a second table acting as a journal. A full sample with CloudFormation is available in the AppSync documentation. The rest of this documentation will focus on the client usage.
You can also use Delta Sync functionality with GraphQL subscriptions, taking advantage of both only sending changes to the clients when they switch network connectivity but also when they are online. In this case you can pass a third query called the “Subscription Query” which is a standard GraphQL subscription statement. When the device is connected, these are processed as normal and the client API simply helps make setting up realtime data easy. However, when the device transitions from offline to online, to account for high velocity writes the client will execute the resubscription along with synchronization and message processing in the following order:
- Subscribe to any queries defined and store results in an incoming queue
- Run the appropriate query (If
baseRefreshIntervalInSecondshas elapsed, run the Base Query otherwise only run the Delta Query) - Update the cache with results from the appropriate query
- Drain the subscription queue and continue processing as normal
Finally, you might have other queries which you wish to represent in your application other than the base cache hydration. For instance a getItem(id:ID) or other specific query. If your alternative query corresponds to items which are already in the normalized cache, you can point them at these cache entries with the cacheUpdates function which returns an array of queries and their variables. The DeltaSync client will then iterate through the items and populate a query entry for each item on your behalf. If you wish to use additional queries which don’t correspond to items in your base query cache, you can always create another instance of the client.sync() process.
Usage
// Start DeltaSync
const subscription = client.sync(options)
/*
Under the covers, this is actually an Observable<T> that the AppSync client automatically subscribes to for you, so the returned object is a "subscription". This means that you can automatically stop the syncronization process like so:
*/
// Stop DeltaSync
subscription.unsubscribe();
The options object
baseQuery
query: ADocumentNodefor the base data (e.g. as returned bygql)variables[optional]: An object with the query variables, if any.baseRefreshIntervalInSeconds[optional]: Number of seconds after which the base query will be run again. Default value:86400(24 hrs)update[optional]: A function to update the cache, see: Apollo’supdatefunction
subscriptionQuery
query: ADocumentNodefor the subscription (e.g. as returned bygql)variables[optional]: An object with the query variables, if any.update[optional]: A function to update the cache, see: Apollo’supdatefunction
deltaQuery
query: ADocumentNodefor the deltas (e.g. as returned bygql)variables[optional]: An object with the query variables, if any.update[optional]: A function to update the cache, see: Apollo’supdatefunction
The buildSync helper
The quickest way to get started with the DeltaSync feature is by using the buildSync helper function. This helper function will build an options object with the appropriate update functions that will update the cache for you in a similar fashion to the offline helpers.
The first argument you need to pass is the GraphQL __typename for your base query. The second argument is the options object from the previous section (without the update keys, since those will be generated for you by this helper function).
You can optionally pass a cacheUpdates parameter to the second argument with the following structure:
- deltaRecord: A function which receives a
deltaRecord(e.g. an individual item in the cache populated by the base/delta/subscription query) and returns an array of GraphQL queries and it’s variables to be written to the cache.
Example:
client.sync(
buildSync("Post", {
baseQuery: {
query: DeltaSync.BaseQuery
},
subscriptionQuery: {
query: DeltaSync.Subscription
},
deltaQuery: {
query: DeltaSync.DeltaSync
},
cacheUpdates: ( deltaRecord ) => {
const id = deltaRecord.id;
return [{ query: DeltaSync.GetItem, variables: { id: id } }];
}
})
)
Requirements for helper function
- Your
baseQueryreturns a list, not a nested type - Your
deltaQueryexpects a parameter calledlastSyncof typeAWSTimestampand returns a list with the same fields as yourbaseQuery(an optionally, anaws_dsfield with a value of'DELETE'for deletions, any other value for insert/update) - The mutations that trigger the subscription in your
subscriptionQueryshould return a single record with the same fields as the items from yourbaseQuery, (an optionally, anaws_dsfield with a value of'DELETE'for deletions, any other value for insert/update)
Example
The schema for this sample is below. A full sample with CloudFormation is available in the AppSync documentation.
input CreatePostInput {
author: String!
title: String!
content: String!
url: String
ups: Int
downs: Int
}
enum DeltaAction {
DELETE
}
type Mutation {
createPost(input: CreatePostInput!): Post
updatePost(input: UpdatePostInput!): Post
deletePost(id: ID!): Post
}
type Post {
id: ID!
author: String!
title: String!
content: String!
url: AWSURL
ups: Int
downs: Int
createdDate: String
aws_ds: DeltaAction
}
type Query {
getPost(id: ID!): Post
listPosts: [Post]
listPostsDelta(lastSync: AWSTimestamp): [Post]
}
type Subscription {
onDeltaPost: Post
@aws_subscribe(mutations: ["createPost","updatePost","deletePost"])
}
input UpdatePostInput {
id: ID!
author: String
title: String
content: String
url: String
ups: Int
downs: Int
}
schema {
query: Query
mutation: Mutation
subscription: Subscription
}
Sample queries
query Base {
listPosts {
id
title
author
content
}
}
query Delta($lastSync: AWSTimestamp!) {
listPostsDelta(
lastSync: $lastSync
) {
id
title
author
content
aws_ds
}
}
subscription Subscription {
onDeltaPost {
id
title
author
content
aws_ds
}
}
Define the queries from above in a ./graphql/DeltaSync.js file to import in your app:
import gql from "graphql-tag";
export const BaseQuery = gql`query Base{
listPosts {
id
title
author
content
}
}`;
export const GetItem = gql`query GetItem($id: ID!){
getPost(id: $id) {
id
title
author
content
}
}`;
export const Subscription = gql`subscription Subscription {
onDeltaPost {
id
title
author
content
}
}`;
export const DeltaSync = gql`query Delta($lastSync: AWSTimestamp!) {
listPostsDelta(
lastSync: $lastSync
) {
id
title
author
content
aws_ds
}
}`;
import { AWSAppSyncClient, buildSync } from "aws-appsync";
import * as DeltaSync from "./graphql/DeltaSync";
const client = new AWSAppSyncClient({
// ...
});
const subscription = client.sync(
buildSync('Post', {
baseQuery: { query: DeltaSync.BaseQuery },
subscriptionQuery: { query: DeltaSync.Subscription },
deltaQuery: { query: DeltaSync.DeltaSync },
cacheUpdates : ({id}) => [{query: DeltaSync.getItem, variables: {id}]
})
);
React example
Suppose you have an app created with Create React App with the following structure:
- App.js
- Sets up
AWSAppSyncClientandclient.syncas above - Renders
<AllPosts />and<SinglePost item={2}>
- Sets up
- AllPosts.jsx exports
<AllPosts /> - GetPost.jsx exports
<SinglePost item={id}>
App.js
const client = new AWSAppSyncClient({
url: awsconfig.aws_appsync_graphqlEndpoint,
region: awsconfig.aws_appsync_region,
auth: {
type: awsconfig.aws_appsync_authenticationType,
apiKey: awsconfig.aws_appsync_apiKey
}
});
client.hydrated().then(() =>
client.sync(
buildSync("Post", {
baseQuery: {
query: DeltaSync.BaseQuery
},
subscriptionQuery: {
query: DeltaSync.Subscription
},
deltaQuery: {
query: DeltaSync.DeltaSync
},
cacheUpdates: ({ id }) => [
{ query: DeltaSync.GetItem, variables: { id } }
]
})
)
);
const App = () => (
<ApolloProvider client={client}>
<Rehydrated>
<div>
<OnePost id="96d5e889-38ba-4846-84d0-a11d6447d34b" />
<hr />
<AllPosts />
</div>
</Rehydrated>
</ApolloProvider>
);
In AllPosts.jsx you would have code like so:
const AllPosts = ({ postsList }) => (
<div>
<pre style={{ textAlign: "left" }}>
{JSON.stringify(postsList, null, 2)}
</pre>
</div>
);
export default graphql(DeltaSync.BaseQuery, {
options: {
fetchPolicy: "cache-only"
},
props: ({ data }) => ({
postsList: data.listPosts || []
})
})(AllPosts);
In GetPost.jsx you would have:
const OnePost = ({ post }) => (
<div>
<pre style={{ textAlign: "left" }}>{JSON.stringify(post, null, 2)}</pre>
</div>
);
export default graphql(DeltaSync.GetItem, {
options: ({ id }) => ({
variables: { id },
fetchPolicy: "cache-only"
}),
props: ({ data: { getPost } }) => ({
post: getPost
})
})(OnePost);
Note: The fetchPolicy is cache-only as all of the network requests are handled automatically by the client.sync() operation. You should use this if using different queries in other components as the client.sync() API manages the cache lifecycle. If you use another fetch-policy such as cache-and-network then extra network requests may take place negating the Delta Sync benefits.
Writing update functions
If you do not want to use the buildSync helper then you are responsible for managing cache updates in your application code. Note that this can be a complex process as you will need to manage create, update, and deletes appropriately. An example of this would be updating the cache with a delta record as below, noting that you must update the returned type to match the type from your base query.
client.sync({
baseQuery: { query: DeltaSyncQueries.BaseQuery },
deltaQuery: {
query: DeltaSyncQueries.DeltaSync,
update: (cache, { data: { listPostsDelta } }) => {
const query = DeltaSyncQueries.GetItem;
listPostsDelta.forEach(deltaRecord => {
const variables = { id: deltaRecord.id };
cache.writeQuery({
query,
variables,
data: { getPost: { ...deltaRecord, __typename: 'Post' } }
});
});
}
}
});
AWS AppSync Multi-Auth
AWS AppSync can support multiple authorization modes on a single API. In order to use this feature with the aws-appsync SDK, you can create multiple instances of the client where each instance uses a different authorization type.
Using different clients is supported in the following UI bindings for Apollo:
Offline capabilities disabled (disableOffline: true)
import Amplify, { Auth } from "aws-amplify";
import AWSAppSyncClient, { AUTH_TYPE } from "aws-appsync";
import awsConfig from "./aws-exports";
Amplify.configure(awsConfig);
// Client 1 uses API_KEY as auth type
const client1 = new AWSAppSyncClient({
url: awsConfig.aws_appsync_graphqlEndpoint,
region: awsConfig.aws_appsync_region
auth: { type: AUTH_TYPE.API_KEY, apiKey: awsConfig.aws_appsync_apiKey},
disableOffline: true,
});
// Client 2 uses AMAZON_COGNITO_USER_POOLS as auth type, leverages Amplify's token handling/refresh
const client2 = new AWSAppSyncClient({
url: awsConfig.aws_appsync_graphqlEndpoint,
region: awsConfig.aws_appsync_region
auth: {
type: AUTH_TYPE.AMAZON_COGNITO_USER_POOLS,
jwtToken: async () => (await Auth.currentSession()).getIdToken().getJwtToken(),
disableOffline: true,
}
});
Offline capabilities enabled
Multiple clients cannot share the same keyPrefix since it is used to separate each client’s persisted data (e.g. cache). When using multiple clients, make sure that you provide a different keyPrefix in the offlineConfig object.
import Amplify, { Auth } from "aws-amplify";
import AWSAppSyncClient, { AUTH_TYPE } from "aws-appsync";
import awsConfig from "./aws-exports";
Amplify.configure(awsConfig);
// Client 1 uses API_KEY as auth type
const client1 = new AWSAppSyncClient({
url: awsConfig.aws_appsync_graphqlEndpoint,
region: awsConfig.aws_appsync_region
auth: { type: AUTH_TYPE.API_KEY, apiKey: awsConfig.aws_appsync_apiKey},
offlineConfig: {
keyPrefix: 'public'
}
});
// Client 2 uses AWS_IAM as auth type, leverages Amplify's credentials handling/refresh
const client2 = new AWSAppSyncClient({
url: awsConfig.aws_appsync_graphqlEndpoint,
region: awsConfig.aws_appsync_region
auth: { type: AUTH_TYPE.AWS_IAM, credentials: () => Auth.currentCredentials() },
offlineConfig: {
keyPrefix: 'private'
}
});
Angular
Amplify CLI generates APIService to make it easier to use Appsync API. Add an GraphQL API by running add api command in your project root folder
$ amplify add api
? Please select from one of the below mentioned services GraphQL
? Provide API name: angularcodegentest
? Choose an authorization type for the API API key
? Do you have an annotated GraphQL schema? No
? Do you want a guided schema creation? true
? What best describes your project: (Use arrow keys)
? What best describes your project: Single object with fields (e.g., “Todo” with ID, name, description)
? Do you want to edit the schema now? (Y/n) n
? Do you want to edit the schema now? No
Push the API to cloud by running $amplify push
amplify push
| Category | Resource name | Operation | Provider plugin |
| -------- | ------------------ | --------- | ----------------- |
| Api | angularcodegentest | Create | awscloudformation |
? Are you sure you want to continue? true
GraphQL schema compiled successfully. Edit your schema at /Users/yathiraj/Documents/code/angular-codegen-test/amplify/backend/api/angularcodegentest/schema.graphql
? Do you want to generate code for your newly created GraphQL API (Y/n)
? Do you want to generate code for your newly created GraphQL API Yes
? Choose the code generation language target (Use arrow keys)
? Choose the code generation language target angular
? Enter the file name pattern of graphql queries, mutations and subscriptions (src/graphql/**/*.graphql)
? Enter the file name pattern of graphql queries, mutations and subscriptions src/graphql/**/*.graphql
? Do you want to generate/update all possible GraphQL operations - queries, mutations and subscriptions (Y/n)
? Do you want to generate/update all possible GraphQL operations - queries, mutations and subscriptions Yes
? Enter the file name for the generated code (src/app/API.service.ts)
? Enter the file name for the generated code src/app/API.service.ts
...
...
...
...
✔ Code generated successfully and saved in file src/app/API.service.ts
✔ Generated GraphQL operations successfully and saved at src/graphql
✔ All resources are updated in the cloud
Configure your Angular app to use the aws-exports. Rename the generated aws-exports.js -> aws-exports.ts and import it in main.ts
// file: src/main.ts
// ...
import PubSub from '@aws-amplify/pubsub';
import API from '@aws-amplify/api';
import awsconfig from './aws-exports';
PubSub.configure(awsconfig);
API.configure(awsconfig);
// ...
Expose the APIService from the root of your app
// file: src/app/app.module.ts
// ...
import { AppComponent } from './app.component';
import { APIService } from './API.service';
// ...
@NgModule({
declarations: [
AppComponent
],
imports: [
BrowserModule
],
providers: [APIService],
bootstrap: [AppComponent]
})
export class AppModule { }
In your component use the API service
// file: app.component.ts
// ...
import { APIService } from './API.service';
// ...
export class AppComponent {
constructor(private apiService: APIService) {}
}
APIService exposes all the queries and subscription as methods
// file: app.component.ts
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent {
title = 'angular-codegen-test';
constructor(private apiService: APIService) {
this.onNewTodo()
}
async createTodo() {
const response = await this.apiService.CreateTodo({description: 'foo', name: 'bar'});
console.log(response);
}
async onNewTodo() {
this.apiService.OnCreateTodoListener.subscribe((next) => {
console.log(next.value.OnCreateTodo);
});
}
}
Using REST
The API category can be used for creating signed requests against Amazon API Gateway when the API Gateway Authorization is set to AWS_IAM.
Ensure you have installed and configured the Amplify CLI and library.
Automated Setup
Run the following command in your project’s root folder:
$ amplify add api
Select REST as the service type.
? Please select from one of the below mentioned services
GraphQL
❯ REST
The CLI will prompt several options to create your resources. With the provided options you can create:
- REST endpoints that triggers Lambda functions
- REST endpoints which enables CRUD operations on an Amazon DynamoDB table
During setup you can use existing Lambda functions and DynamoDB tables or create new ones by following the CLI prompts. After your resources have been created update your backend with the push command:
$ amplify push
A configuration file called aws-exports.js will be copied to your configured source directory, for example ./src.
Configure Your App
Import and load the configuration file in your app. It’s recommended you add the Amplify configuration step to your app’s root entry point. For example App.js in React or main.ts in Angular.
import Amplify, { API } from 'aws-amplify';
import awsconfig from './aws-exports';
Amplify.configure(awsconfig);
Manual Setup
For manual configuration you need to provide your AWS Resource configuration and optionally configure authentication.
import Amplify, { API } from 'aws-amplify';
Amplify.configure({
// OPTIONAL - if your API requires authentication
Auth: {
// REQUIRED - Amazon Cognito Identity Pool ID
identityPoolId: 'XX-XXXX-X:XXXXXXXX-XXXX-1234-abcd-1234567890ab',
// REQUIRED - Amazon Cognito Region
region: 'XX-XXXX-X',
// OPTIONAL - Amazon Cognito User Pool ID
userPoolId: 'XX-XXXX-X_abcd1234',
// OPTIONAL - Amazon Cognito Web Client ID (26-char alphanumeric string)
userPoolWebClientId: 'a1b2c3d4e5f6g7h8i9j0k1l2m3',
},
API: {
endpoints: [
{
name: "MyAPIGatewayAPI",
endpoint: "https://1234567890-abcdefgh.amazonaws.com"
},
{
name: "MyCustomCloudFrontApi",
endpoint: "https://api.my-custom-cloudfront-domain.com",
}
]
}
});
AWS Regional Endpoints
You can utilize regional endpoints by passing in the service and region information to the configuration. See AWS Regions and Endpoints. The example below defines a Lambda invocation in the us-east-1 region:
API: {
endpoints: [
{
name: "MyCustomLambda",
endpoint: "https://lambda.us-east-1.amazonaws.com/2015-03-31/functions/yourFuncName/invocations",
service: "lambda",
region: "us-east-1"
}
]
}
Note THIS IS NOT RECOMMENDED ARCHITECTURE and we highly recommend you leverage AWS AppSync or API Gateway as the endpoint to invoke your Lambda functions.
Configuring Amazon Cognito Regional Endpoints To call regional service endpoints, your Amazon Cognito role needs to be configured with appropriate access for the related service. See AWS Cognito Documentation for more details.
Using the API Client
To invoke a REST API, you need the name for the related endpoint. If you manually configure the API, you already have a name for the endpoint. If you use Automated Setup, you can find the API name in your local configuration file.
The following code sample assumes that you have used Automated Setup.
To invoke an endpoint, you need to set apiName, path and headers parameters, and each method returns a Promise.
Under the hood the API category utilizes Axios to execute the HTTP requests. API status code response > 299 are thrown as an exception. If you need to handle errors managed by your API, work with the error.response object.
GET
let apiName = 'MyApiName';
let path = '/path';
let myInit = { // OPTIONAL
headers: {}, // OPTIONAL
response: true, // OPTIONAL (return the entire Axios response object instead of only response.data)
queryStringParameters: { // OPTIONAL
name: 'param'
}
}
API.get(apiName, path, myInit).then(response => {
// Add your code here
}).catch(error => {
console.log(error.response)
});
Example with async/await
async getData() {
let apiName = 'MyApiName';
let path = '/path';
let myInit = { // OPTIONAL
headers: {} // OPTIONAL
}
return await API.get(apiName, path, myInit);
}
getData();
Using Query Parameters
To use query parameters with get method, you can pass them in queryStringParameters parameter in your method call:
let items = await API.get('myCloudApi', '/items', {
'queryStringParameters': {
'order': 'byPrice'
}
});
Accessing Query Parameters & body in Cloud API
If you are using a Cloud API which is generated with Amplify CLI, your backend is created with Lambda Proxy Integration, and you can access your query parameters & body within your Lambda function via the event object:
exports.handler = function(event, context, callback) {
console.log (event.queryStringParameters);
console.log('body: ', event.body)
}
Alternatively, you can update your backend file which is located at amplifyjs/backend/function/[your-lambda-function]/app.js with the middleware:
const awsServerlessExpressMiddleware = require('aws-serverless-express/middleware');
app.use(awsServerlessExpressMiddleware.eventContext())
Accessing Query Parameters with Serverless Express
In your request handler use req.apiGateway.event or req.query:
app.get('/items', function(req, res) {
const query = req.query
// or
// const query = req.apiGateway.event.queryStringParameters
res.json({
event: req.apiGateway.event, // to view all event data
query: query
})
});
Then you can use query parameters in your path as follows:
API.get('sampleCloudApi', '/items?q=test');
To learn more about Lambda Proxy Integration, please visit Amazon API Gateway Developer Guide.
Custom Response Type
By default, calling an API with AWS Amplify parses a JSON response. If you have a REST API endpoint which returns, for example, a file in Blob format, you can specify a custom response type using the responseType parameter in your method call:
let file = await API.get('myCloudApi', '/items', {
'responseType': 'blob'
});
Allowed values for responseType are “arraybuffer”, “blob”, “document”, “json” or “text”; and it defaults to “json” if not specified. See the documentation https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest/responseType for more information.
POST
Posts data to the API endpoint:
let apiName = 'MyApiName'; // replace this with your api name.
let path = '/path'; //replace this with the path you have configured on your API
let myInit = {
body: {}, // replace this with attributes you need
headers: {} // OPTIONAL
}
API.post(apiName, path, myInit).then(response => {
// Add your code here
}).catch(error => {
console.log(error.response)
});
Example with async/await
async function postData() {
let apiName = 'MyApiName';
let path = '/path';
let myInit = { // OPTIONAL
body: {}, // replace this with attributes you need
headers: {} // OPTIONAL
}
return await API.post(apiName, path, myInit);
}
postData();
Access body in the Lambda function
// using a basic lambda handler
exports.handler = (event, context) => {
console.log('body: ', event.body);
}
// using serverless express
app.post('/myendpoint', function(req, res) {
console.log('body: ', req.body)
});
PUT
When used together with a Cloud API, PUT method can be used to create or update records. It updates the record if a matching record is found. Otherwise, a new record is created.
let apiName = 'MyApiName'; // replace this with your api name.
let path = '/path'; // replace this with the path you have configured on your API
let myInit = {
body: {}, // replace this with attributes you need
headers: {} // OPTIONAL
}
API.put(apiName, path, myInit).then(response => {
// Add your code here
}).catch(error => {
console.log(error.response)
});
Example with async/await:
async function putData() {
let apiName = 'MyApiName';
let path = '/path';
let myInit = { // OPTIONAL
body: {}, // replace this with attributes you need
headers: {} // OPTIONAL
}
return await API.put(apiName, path, myInit);
}
putData();
Access body in the Lambda function
// using a basic lambda handler
exports.handler = (event, context) => {
console.log('body: ', event.body);
}
// using serverless express
app.put('/myendpoint', function(req, res) {
console.log('body: ', req.body)
});
Update a record:
const params = {
body: {
itemId: '12345',
itemDesc: ' update description'
}
}
const apiResponse = await API.put('MyTableCRUD', '/manage-items', params);
DELETE
let apiName = 'MyApiName'; // replace this with your api name.
let path = '/path'; //replace this with the path you have configured on your API
let myInit = { // OPTIONAL
headers: {} // OPTIONAL
}
API.del(apiName, path, myInit).then(response => {
// Add your code here
}).catch(error => {
console.log(error.response)
});
Example with async/await
async function deleteData() {
let apiName = 'MyApiName';
let path = '/path';
let myInit = { // OPTIONAL
headers: {} // OPTIONAL
}
return await API.del(apiName, path, myInit);
}
deleteData();
Access body in the Lambda function
// using a basic lambda handler
exports.handler = (event, context) => {
console.log('body: ', event.body);
}
// using serverless express
app.delete('/myendpoint', function(req, res) {
console.log('body: ', req.body)
});
HEAD
let apiName = 'MyApiName'; // replace this with your api name.
let path = '/path'; //replace this with the path you have configured on your API
let myInit = { // OPTIONAL
headers: {} // OPTIONAL
}
API.head(apiName, path, myInit).then(response => {
// Add your code here
});
Example with async/await:
async function head() {
let apiName = 'MyApiName';
let path = '/path';
let myInit = { // OPTIONAL
headers: {} // OPTIONAL
}
return await API.head(apiName, path, myInit);
}
head();
Custom Request Headers
When working with a REST endpoint, you may need to set request headers for authorization purposes. This is done by passing a custom_header function into the configuration:
Amplify.configure({
API: {
endpoints: [
{
name: "sampleCloudApi",
endpoint: "https://xyz.execute-api.us-east-1.amazonaws.com/Development",
custom_header: async () => {
return { Authorization : 'token' }
// Alternatively, with Cognito User Pools use this:
// return { Authorization: `Bearer ${(await Auth.currentSession()).getAccessToken().getJwtToken()}` }
}
}
]
}
});
Unauthenticated Requests
You can use the API category to access API Gateway endpoints that don’t require authentication. In this case, you need to allow unauthenticated identities in your Amazon Cognito Identity Pool settings. For more information, please visit Amazon Cognito Developer Documentation.
Customization
Customizing HTTP Request Headers
To use custom headers on your HTTP request, you need to add these to Amazon API Gateway first. For more info about configuring headers, please visit Amazon API Gateway Developer Guide
If you have used Amplify CLI to create your API, you can enable custom headers by following above steps:
- Visit Amazon API Gateway console.
- On Amazon API Gateway console, click on the path you want to configure (e.g. /{proxy+})
- Then click the Actions dropdown menu and select Enable CORS
- Add your custom header (e.g. my-custom-header) on the text field Access-Control-Allow-Headers, separated by commas, like: ‘Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token,my-custom-header’.
- Click on ‘Enable CORS and replace existing CORS headers’ and confirm.
- Finally, similar to step 3, click the Actions drop-down menu and then select Deploy API. Select Development on deployment stage and then Deploy. (Deployment could take a couple of minutes).
Cognito User Pools Authorization
You can use the JWT token provided by the Authentication API to authenticate against API Gateway directly when using a custom authorizer. You can achieve this by retrieving the JWT token from the (await Auth.currentSession()).getIdToken().getJwtToken() API:
async function postData() {
let apiName = 'MyApiName';
let path = '/path';
let myInit = {
headers: { Authorization: `Bearer ${(await Auth.currentSession()).getIdToken().getJwtToken()}` }
}
return await API.post(apiName, path, myInit);
}
postData();
Note that the header name, in the above example ‘Authorization’, is dependent on what you choose during your API Gateway configuration.
Using Modular Imports
If you only need to use API, you can run: npm install @aws-amplify/api which will only install the API module.
Note: if you’re using Cognito Federated Identity Pool to get AWS credentials, please also install @aws-amplify/auth.
Note: if you’re using Graphql, please also install @aws-amplify/pubsub
Then in your code, you can import the Api module by:
import API, { graphqlOperation } from '@aws-amplify/api';
API.configure();
API Reference
For the complete API documentation for API module, visit our API Reference