

Quickstart
Installation
The Amplify Command Line Interface (CLI) is a unified toolchain to create, integrate, and manage the AWS cloud services for your app.
- Install Node.js® and NPM if they are not already on your machine.
- Verify that you are running at least Node.js version 10.x and npm version 6.x or greater by running
node -vand npm -v in a terminal/console window - Install and configure the Amplify CLI.
$ npm install -g @aws-amplify/cli
$ amplify configure
Concepts
The Amplify CLI toolchain is designed to work with the Amplify JavaScript library as well as the AWS Mobile SDKs for iOS and Android. Resources in your AWS account that the Amplify CLI category commands create can be easily consumed by the corresponding Amplify library modules or native SDKs.
The Amplify CLI is written in Node.js. It has a pluggable architecture and can be easily extended with additional functionalities.
Click here for more details.
Typical CLI workflow
The following commands should be executed inside your project root directory:
amplify initamplify <category> add/removeamplify pushamplify pull
The init process
$ amplify init
The init command must be executed at the root directory of a project to initialize the project for the Amplify CLI to work with.
The init command goes through the following steps:
- Analyzes the project and confirms the frontend settings
- Carries out the initialization logic of the selected frontend
- If there are multiple provider plugins, prompts to select the plugins that will provide accesses to cloud resources
- Carries out, in sequence, the initialization logic of the selected plugin(s)
- Insert amplify folder structure into the project’s root directory, with the initial project configuration
- Generate the project metadata files, with the outputs of the above-selected plugin(s)
- Creates a cloud project in the AWS Amplify Console to view and manage resources for all backend environments.
Samples workflow
To set up a sample amplify project, execute the following command inside an empty directory:
amplify init --app <github url>
where the github url is a valid sample amplify project repository. Click here for more details.
Common CLI commands
amplify <category> <subcommand>amplify pushamplify pullamplify env <subcommand>amplify configureamplify consoleamplify deleteamplify helpamplify initamplify publishamplify runamplify status
Most categories have the following command structure
amplify <category> addamplify <category> removeamplify <category> push
amplify init
During the init process, the root stack is created with three resources:
- IAM role for unauthenticated users
- IAM role for authenticated users
- S3 bucket, the deployment bucket, to support this provider’s workflow
The provider logs the information of the root stack and the resources into the project metadata file (amplify/backend/amplify-meta.json).
The root stack’s template can be found in amplify/backend/awscloudformation.
amplify add
Once init is complete, run the command amplify add <category> to add resources of a category to the cloud. This will place a CloudFormation template for the resources of this category in the category’s subdirectory amplify/backend/<category> and insert its reference into the above-mentioned root stack as the nested child stack. When working in teams, it is good practice to run an amplify pull before modifying the backend categories.
amplify push
Once you have made your category updates, run the command amplify push to update the cloud resources. The CLI will first upload the latest versions of the category nested stack templates to the S3 deployment bucket, and then call the AWS CloudFormation API to create / update resources in the cloud. Based upon the resources added/updated, the aws-exports.js file (for JS projects) and the awsconfiguration.json file (for native projects) gets created/updated.
amplify pull
The amplify pull command operates similar to a git pull, fetching upstream backend environment definition changes from the cloud and updating the local environment to match that definition. The command is particularly helpful in team scenarios when multiple team members are editing the same backend, pulling a backend into a new project, or when connecting to multiple frontend projects that share the same Amplify backend environment.
amplify console
The amplify console command launches the browser directing you to your cloud project in the AWS Amplify Console. The Amplify Console provides a central location for development teams to view and manage their backend environments, status of the backend deployment, deep-links to the backend resources by Amplify category, and instructions on how to pull, clone, update, or delete environments.
amplify configure project
The amplify configure project command is an advanced command and not commonly used for getting started or individual development projects. The command should be used to modify the project configuration present in the .config/ directory and re-configuring AWS credentials (based on profile on your local machine) set up during the amplify init step. The .config/ directory is generated in the amplify/ directory, if not already present, and the local-aws-info.json, local-env-info.json and project-info.json files are configured to reflect the selections made as a part of the amplify configure project command.
Category usage
Auth Examples
The Amplify CLI supports configuring many different Authentication and Authorization workflows, including simple and advanced configurations of the login options, triggering Lambda functions during different lifecycle events, and administrative actions which you can optionally expose to your applications.
Configuring auth without social providers
The easiest way to get started is to leverage the default configuration which is optimized for the most common use cases and choices.
$ amplify add auth ##"amplify update auth" if already configured
Do you want to use the default authentication and security configuration?
❯ Default configuration
Default configuration with Social Provider (Federation)
Manual configuration
I want to learn more.
Configuring auth with social providers
Once your User Pool is functioning, you can enable more configurations such as federation with Facebook, Google, or Login with Amazon. You can also configure more advanced settings by selecting Manual Configuration.
$ amplify add auth ##"amplify update auth" if already configured
Select Default configuration with Social Provider (Federation):
Do you want to use the default authentication and security configuration?
Default configuration
❯ Default configuration with Social Provider (Federation)
Manual configuration
I want to learn more.
Group management
You can create logical Groups in Cognito User Pools and assign permissions to access resources in Amplify categories with the CLI, as well as define the relative precedence of one group to another. This can be useful for defining which users should be part of “Admins” vs “Editors”, and if the users in a Group should be able to just write or write & read to a resource (AppSync, API Gateway, S3 bucket, etc). You can also use these with @auth Static Groups in the GraphQL Transformer. Precedence helps remove any ambiguity on permissions if a user is in multiple Groups.
$ amplify add auth
❯ Manual configuration
Do you want to add User Pool Groups? (Use arrow keys)
❯ Yes
? Provide a name for your user pool group: Admins
? Do you want to add another User Pool Group Yes
? Provide a name for your user pool group: Editors
? Do you want to add another User Pool Group No
? Sort the user pool groups in order of preference … (Use <shift>+<right/left> to change the order)
Admins
Editors
When asked as in the example above, you can press Shift on your keyboard along with the LEFT and RIGHT arrows to move a Group higher or lower in precedence. Once complete you can open ./amplify/backend/auth/userPoolGroups/user-pool-group-precidence.json to manually set the precedence.
Group access controls
For certain Amplify categories you can restrict access with CRUD (Create, Read, Update, and Delete) permissions, setting different access controls for authenticated users vs Guests (e.g. Authenticated users can read & write to S3 buckets while Guests can only read). You can further restrict this to apply different permissions conditionally depending on if a logged-in user is part of a specific User Pool Group.
$ amplify add storage # Select content
? Restrict access by? (Use arrow keys)
Auth/Guest Users
Individual Groups
❯ Both
Learn more
Who should have access?
❯ Auth and guest users
What kind of access do you want for Authenticated users?
❯ create/update, read
What kind of access do you want for Guest users?
❯ read
Select groups:
❯ Admins
What kind of access do you want for Admins users?
❯ create/update, read, delete
The above example uses a combination of permissions where users in the “Admins” Group have full access, Guest users can only read, and users whom are not a member of any specific Group are part of the “Authenticated” users whom have create, update, and read access. Amplify will configure the corresponding IAM policy on your behalf. Advanced users can additionally set permissions by adding a customPolicies key to ./amplify/backend/auth/userPoolGroups/user-pool-group-precidence.json with custom IAM policy for a Group. This will attach an inline policy on the IAM role associated to this Group during deployment. Note this is an advanced feature and only suitable if you have an understanding of AWS resources. For instance perhaps you wanted users in the “Admins” group to have the ability to Create an S3 bucket:
[
{
"groupName": "Admins",
"precedence": 1,
"customPolicies": [{
"PolicyName": "admin-group-policy",
"PolicyDocument": {
"Version":"2012-10-17",
"Statement":[
{
"Sid":"statement1",
"Effect":"Allow",
"Action":[
"s3:CreateBucket"
],
"Resource":[
"arn:aws:s3:::*"
]
}
]
}
}]
},
{
"groupName": "Editors",
"precedence": 2
}
]
Administrative Actions
In some scenarios you may wish to expose Administrative actions to your end user applications. For example, the ability to list all users in a Cognito User Pool may provide useful for the administrative panel of an app if the logged-in user is a member of a specific Group called “Admins”.
This is an advanced feature that is not recommended without an understanding of the underlying architecture. The associated infrastructure which is created is a base designed for you to customize for your specific business needs. We recommend removing any functionality which your app does not require.
The Amplify CLi can setup a REST endpoint with secure access to a Lambda function running with limited permissions to the User Pool if you wish to have these capabilities in your application, and you can choose to expose the actions to all users with a valid account or restrict to a specific User Pool Group.
$ amplify add auth
# Choose default or manual
? Do you want to add an admin queries API? Yes
? Do you want to restrict access to a specific Group Yes
? Select the group to restrict access with: (Use arrow keys)
❯ Admins
Editors
Enter a custom group
This will configure an API Gateway endpoint with a Cognito Authorizer that accepts an Access Token, which is used by a Lambda function to perform actions against the User Pool. The function is example code which you can use to remove, add, or alter functionality based on your business case by editing it in the ./amplify/backend/function/AdminQueriesXXX/src directory and running an amplify push to deploy your changes. If you choose to restrict actions to a specific Group, custom middleware in the function will prevent any actions unless the user is a member of that Group.
The default routes and their functions, HTTP methods, and expected parameters are below
addUserToGroup: Adds a user to a specific Group. Expectsusernameandgroupnamein the POST body.removeUserFromGroup: Adds a user to a specific Group. Expectsusernameandgroupnamein the POST body.confirmUserSignUp: Adds a user to a specific Group. Expectsusernamein the POST body.disableUser: Adds a user to a specific Group. Expectsusernamein the POST body.enableUser: Adds a user to a specific Group. Expectsusernamein the POST body.getUser: Adds a user to a specific Group. Expectsusernameas a GET query string.listUsers: Adds a user to a specific Group. You can provide an OPTIONALlimitas a GET query string, which returns aNextTokenthat can be provided as atokenquery string for pagination.listGroupsForUser: Adds a user to a specific Group. Expectsusernameas a GET query string. You can provide an OPTIONALlimitas a GET query string, which returns aNextTokenthat can be provided as atokenquery string for pagination.listUsersInGroup: Adds a user to a specific Group. Expectsgroupnameas a GET query string. You can provide an OPTIONALlimitas a GET query string, which returns aNextTokenthat can be provided as atokenquery string for pagination.signUserOut: Signs a user out from User Pools, but only if the call is originating from that user. Expectsusernamein the POST body.
To leverage this functionality in your app you would call the appropriate route in your JavaScript, iOS, or Android application after signing in. For example to add a user “richard” to the Editors Group and then list all members of the Editors Group with a pagination limit of 10 you could use the following React code below:
import React from 'react'
import Amplify, { Auth, API } from 'aws-amplify';
import { withAuthenticator } from 'aws-amplify-react';
import awsconfig from './aws-exports';
Amplify.configure(awsconfig);
async function addToGroup() {
let apiName = 'AdminQueries';
let path = '/addUserToGroup';
let myInit = {
body: {
"username" : "richard",
"groupname": "Editors"
},
headers: {
'Content-Type' : 'application/json',
Authorization: `${(await Auth.currentSession()).getAccessToken().getJwtToken()}`
}
}
return await API.post(apiName, path, myInit);
}
let nextToken;
async function listEditors(limit){
let apiName = 'AdminQueries';
let path = '/listUsersInGroup';
let myInit = {
queryStringParameters: {
"groupname": "Editors",
"limit": limit,
"token": nextToken
},
headers: {
'Content-Type' : 'application/json',
Authorization: `${(await Auth.currentSession()).getAccessToken().getJwtToken()}`
}
}
const { NextToken, ...rest } = await API.get(apiName, path, myInit);
nextToken = NextToken;
return rest;
}
function App() {
return (
<div className="App">
<button onClick={addToGroup}>Add to Group</button>
<button onClick={() => listEditors(10)}>List Editors</button>
</div>
);
}
export default withAuthenticator(App, true);
Adding a Lambda Trigger
Lambda triggers are useful for adding functionality during certain lifecycles of the user registration and sign-in process of your application. Amplify ships common trigger templates which you can enable and modify (if necessary) through a few simple questions. Alternatively, you can build your own auth challenges manually.
There are two ways to setup Lambda Triggers for your Cognito User Pool.
- In the default Auth CLI workflow, you will be presented with a list of Lambda Trigger templates if you opt to configure advanced settings:
$ Do you want to enable any of the following capabilities?
❯ ◯ Add Google reCaptcha Challenge
◯ Email Verification Link with Redirect
◯ Add User to Group
◯ Email Domain Filtering (blacklist)
◯ Email Domain Filtering (whitelist)
◯ Custom Auth Challenge Flow (basic scaffolding - not for production)
◯ Override ID Token Claims
- In the manual Auth CLI workflow, you will be given the chance to select the options above, but will also be able to manually configure Lambda Trigger templates:
$ Do you want to configure Lambda Triggers for Cognito? Yes
$ Which triggers do you want to enable for Cognito?
◯ Learn More
──────────────
◯ Create Auth Challenge
❯◉ Custom Message
◯ Define Auth Challenge
◯ Post Authentication
◯ Post Confirmation
◯ Pre Sign-up
◯ Verify Auth Challenge Response
◯ Pre Token Generation
$ What functionality do you want to use for Custom Message
◯ Learn More
──────────────
❯◉ Send Account Confirmation Link w/ Redirect
◯ Create your own module
If your manually-configured Lambda Triggers require enhanced permissions, you can run amplify function update after they have been initially configured.
Available Cognito Trigger Templates
The pre-populated templates provided by the Amplify CLI can be found here.
API Examples
REST
REST endpoints which enables CRUD operations on an Amazon DynamoDB table
During the CLI setup, you’ll be guided through to create a new Lambda function with a predefined serverless-express template with routing enabled for your REST API paths with support for CRUD operations to DynamoDB tables (which you can create by following the CLI prompts or use the tables which you’ve already configured using the amplify add storage command).
$ amplify add api
? Please select from one of the below mentioned services REST
? Provide a friendly name for your resource to be used as a label for this category in the project: myRESTAPI
? Provide a path (e.g., /items) /items
? Choose a Lambda source Create a new Lambda function
? Provide a friendly name for your resource to be used as a label for this category in the project: betatest1d2654ef
? Provide the AWS Lambda function name: betatest1d2654ef
? Choose the function template that you want to use:
❯ CRUD function for Amazon DynamoDB table (Integration with Amazon API Gateway and Amazon DynamoDB)
Serverless express function (Integration with Amazon API Gateway)
Lambda trigger
REST endpoints that triggers Lambda functions with a predefined simple serverless-express template
During the CLI setup, you’ll be guided through to create a new Lambda function with a predefined serverless-express template with routing enabled for your REST API paths.
$ amplify add api
? Please select from one of the below mentioned services REST
? Provide a friendly name for your resource to be used as a label for this category in the project: myRESTAPI
? Provide a path (e.g., /items) /items
? Choose a Lambda source Create a new Lambda function
? Provide a friendly name for your resource to be used as a label for this category in the project: betatest1d2654ef
? Provide the AWS Lambda function name: betatest1d2654ef
? Choose the function template that you want to use:
CRUD function for Amazon DynamoDB table (Integration with Amazon API Gateway and Amazon DynamoDB)
❯ Serverless express function (Integration with Amazon API Gateway)
Lambda trigger
REST endpoints backed up by custom lambda function present in the current Amplify project
During the CLI setup, you’ll be guided through to use your own Lambda functions which you’ve initialized as a part of your CLI project using the amplify add function command. This would allow you to have custom logic in your Lambda function and not use the predefined serverless-express templates generated by the CLI as in the examples above.
$ amplify add api
? Please select from one of the below mentioned services REST
? Provide a friendly name for your resource to be used as a label for this category in the project: myRESTAPI
? Provide a path (e.g., /items) /items
? Choose a Lambda source
Create a new Lambda function
❯ Use a Lambda function already added in the current Amplify project
GraphQL
You can spin up a GraphQL API via the Amplify CLI with the following flow:
$ amplify add api
? Please select from one of the below mentioned services (Use arrow keys)
❯ GraphQL
REST
To learn more, take a look at the GraphQL Transformer docs.
Functions Examples
You can add a Lambda function to your project which you can use alongside a REST API or as a datasource, as a part of your GraphQL API using the @function directive.
$ amplify add function
? Provide a friendly name for your resource to be used as a label for this category in the project: lambdafunction
? Provide the AWS Lambda function name: lambdafunction
? Choose the function template that you want to use: (Use arrow keys)
❯ Hello world function
CRUD function for Amazon DynamoDB table (Integration with Amazon API Gateway and Amazon DynamoDB)
Serverless express function (Integration with Amazon API Gateway)
Lambda trigger
- The
Hello World functionwould create a basic hello world Lambda function - The
CRUD function for Amazon DynamoDB table (Integration with Amazon API Gateway and Amazon DynamoDB)function would add a predefined serverless-express Lambda function template for CRUD operations to DynamoDB tables (which you can create by following the CLI prompts or use the tables which you’ve already configured using theamplify add storagecommand) - The
Serverless express function (Integration with Amazon API Gateway)would add a predefined serverless-express Lambda function template with routing enabled for your REST API paths. - Lambda trigger would add a function that will be invoked when new data is pushed to either an AWS Kinesis stream or AWS DynamoDB stream (when DynamoDB table gets updated)
You can update the Lambda execution role policies for your function to access other resources generated and maintained by the CLI, using the CLI
$ amplify update function
Please select the Lambda Function you would want to update: lambdafunction
? Do you want to update permissions granted to this Lambda function to perform on other resources in your project? Yes
? Select the category (Press <space> to select, <a> to toggle all, <i> to invert selection)
❯◉ api
◯ function
◯ storage
◯ auth
? Select the operations you want to permit for betatest (Press <space> to select, <a> to toggle all, <i> to invert selection)
❯◉ create
◯ read
◯ update
◯ delete
You can access the following resource attributes as environment variables from your Lambda function
var environment = process.env.ENV
var region = process.env.REGION
var apiBetatestGraphQLAPIIdOutput = process.env.API_BETATEST_GRAPHQLAPIIDOUTPUT
var apiBetatestGraphQLAPIEndpointOutput = process.env.API_BETATEST_GRAPHQLAPIENDPOINTOUTPUT
Behind the scenes, the CLI automates populating of the resource identifiers for the selected resources as Lambda environment variables which you will see in your function code as well. This process additionally configures CRUD level IAM policies on the Lambda execution role to access these resources from the Lambda function. For instance, you might grant permissions to your Lambda function to read/write to a DynamoDB table in the Amplify project by using the above flow and the appropriate IAM policy would be set on that Lambda function’s execution policy which is scoped to that table only.
GraphQL from Lambda
You can use a Lambda function to call your GraphQL API. For example, deploy a simple Todo model with the following schema in the amplify add api flow:
type Todo @model @auth (
rules: [
{ allow: private, provider: iam, operations: [create] }
]
) {
id: ID!
name: String
description: String
}
In the above example we want your Lambda function to have access to run a single mutation (createTodo) and hence we explicitly mention create in the operations list. To grant access for application users to perform other actions, you can add read, update or delete to the operations list along with create.
Save your changes and create a Lambda function with amplify add function and make sure to add access for your GraphQL API when prompted for in the amplify add function flow. The CLI would automatically configure the Lambda execution IAM role required by the Lambda function to call the GraphQL API. The following function will sign the request and use environment variables for the AppSync and Region that amplify add function created for you.
const https = require('https');
const AWS = require("aws-sdk");
const urlParse = require("url").URL;
const appsyncUrl = process.env.API_BACKENDGRAPHQL_GRAPHQLAPIENDPOINTOUTPUT;
const region = process.env.REGION;
const endpoint = new urlParse(appsyncUrl).hostname.toString();
const graphqlQuery = require('./query.js').mutation;
const apiKey = process.env.API_KEY;
exports.handler = async (event) => {
const req = new AWS.HttpRequest(appsyncUrl, region);
const item = {
input: {
name: "Lambda Item",
description: "Item Generated from Lambda"
}
};
req.method = "POST";
req.headers.host = endpoint;
req.headers["Content-Type"] = "application/json";
req.body = JSON.stringify({
query: graphqlQuery,
operationName: "createTodo",
variables: item
});
if (apiKey) {
req.headers["x-api-key"] = apiKey;
} else {
const signer = new AWS.Signers.V4(req, "appsync", true);
signer.addAuthorization(AWS.config.credentials, AWS.util.date.getDate());
}
const data = await new Promise((resolve, reject) => {
const httpRequest = https.request({ ...req, host: endpoint }, (result) => {
result.on('data', (data) => {
resolve(JSON.parse(data.toString()));
});
});
httpRequest.write(req.body);
httpRequest.end();
});
return {
statusCode: 200,
body: data
};
};
Finally you can define the GraphQL operation you’re running, in this case the createTodo mutation, in a separate query.js file:
module.exports = {
mutation: `mutation createTodo($input: CreateTodoInput!) {
createTodo(input: $input) {
id
name
description
}
}
`
}
Storage Examples
S3 Lambda Triggers
You can associate a trigger to an S3 bucket managed by the Amplify CLI, by following the amplify add/update storage flows. When attempting to add/update an S3 storage resource, you would get the following CLI prompts to add a trigger for it.
? Do you want to add a Lambda Trigger for your S3 Bucket? Yes
? Select from the following options
❯ Choose an existing function from the project
Create a new function
As you can see in the prompt above, you can either choose to use an existing Lambda function created using the CLI as a part of this project using amplify add function or create a new function with a base Lambda function to handle S3 events. We also auto-populate the IAM policies required by the Lambda execution role of the newly created function to access the S3 bucket.
Note: You can associate only one Lambda Function trigger to an S3 bucket.
DynamoDB Lambda Triggers
You can associate a Lambda trigger with a DynamoDB table, managed by the Amplify CLI. There are two ways by which DynamoDB is provisioned by the Amplify CLI
- As a part of the Storage category
- As a part of the GraphQL API (types with @model annotation)
As a part of the Storage category
You can add and manage a DynamoDB table to your Amplify project using the amplify add/update storage flows. When attempting to add/update a DynamoDB storage resource, you would get the following CLI prompts to add a trigger for it.
? Do you want to add a Lambda Trigger for your Table? Yes
? Select from the following options (Use arrow keys)
❯ Choose an existing function from the project
Create a new function
As you can see in the prompt above, you can either choose to use an already existing Lambda function created using the CLI as a part of this project using amplify add function or create a new function with a base Lambda function handle DynamoDB events.
Note: You can associate more than one Lambda Function trigger to a DynamoDB table.
As a part of the GraphQL API (types with @model annotation)
You can also associated a Lambda trigger with any of the GraphQL transformer schema’s DynamoDB backed @models which you can add via amplify add api. GraphQL mutations that result in DynamoDB item changes will in turn result in change records published to DynamoDB streams that can trigger a Lambda function. To create such a function, start with adding a new lambda function with:
$ amplify add function
Proceed by providing a name and selecting a Lambda Trigger template:
? Provide a friendly name for your resource to be used as a label for this category in the project: testtrigger
? Provide the AWS Lambda function name: mytrigger
? Choose the function template that you want to use:
Hello world function
CRUD function for Amazon DynamoDB table (Integration with Amazon API Gateway and Amazon DynamoDB)
Serverless express function (Integration with Amazon API Gateway)
❯ Lambda Trigger
Then select Amazon DynamoDB Stream when prompted with event source question.
? What event source do you want to associate with Lambda trigger (Use arrow keys)
❯ Amazon DynamoDB Stream
Amazon Kinesis Stream
Now select API category graphql @model backed DynamoDB table.
?
> Use API category graphql @model backed DynamoDB table(s) in the current Amplify project
Use storage category DynamoDB table configured in the current Amplify project
Provide the ARN of DynamoDB stream directly
After the above question, you can select one of the types annotated by @model for which you want to add a trigger for.
On completion of the above mentioned flow, a boilerplate lambda function trigger will be created in your amplify/backend/function directory with the following template:
exports.handler = function (event, context) {
console.log(JSON.stringify(event, null, 2));
event.Records.forEach((record) => {
console.log(record.eventID);
console.log(record.eventName);
console.log('DynamoDB Record: %j', record.dynamodb);
});
context.done(null, 'Successfully processed DynamoDB record');
};
record.dynamodb will contain a DynamoDB change json describing the item changed in DynamoDB table.
Please note that it does not represent an original and new item as stored in DynamoDB table. To retrieve a original and new item you need to convert a DynamoDB json to original form:
const AWS = require('aws-sdk');
const records = event.Records.map(record => ({
new: AWS.DynamoDB.Converter.unmarshall(record.dynamodb.NewImage),
old: AWS.DynamoDB.Converter.unmarshall(record.dynamodb.OldImage)
}));
Kinesis Stream Trigger
Amplify Analytics category Kinesis stream resource can be also used as an event source for Lambda triggers. Event published to Kinesis stream will trigger a lambda function. You can add a Kinesis stream to your Amplify project by going through the amplify add analytics flow. To create a Lambda trigger for the Kinesis Stream, start with adding a new lambda function:
$ amplify add function
Proceed by providing a name and selecting a Lambda Trigger template:
? Provide a friendly name for your resource to be used as a label for this category in the project: testtrigger
? Provide the AWS Lambda function name: mytrigger
? Choose the function template that you want to use:
Hello world function
CRUD function for Amazon DynamoDB table (Integration with Amazon API Gateway and Amazon DynamoDB)
Serverless express function (Integration with Amazon API Gateway)
❯ Lambda Trigger
Then select Amazon Kinesis Stream when prompted with event source question and select the resource.
? What event source do you want to associate with Lambda trigger (Use arrow keys)
Amazon DynamoDB Stream
❯ Amazon Kinesis Stream
? Choose a Kinesis event source option (Use arrow keys)
❯ Use Analytics category kinesis stream in the current Amplify project
Provide the ARN of Kinesis stream directly
After the completion of the above flow, a Lambda function will be created in your amplify/backend/function directory and will be invoked when a new event is pushed to a Kinesis stream. Please refer to Working with the API to learn more about publishing your events to Kinesis stream.
Mocking and Testing
It is highly recommended that you complete the Getting Started section of Amplify setup before using local mocking.
Amplify supports running a local server for mocking and testing your application before pushing to the cloud with certain categories, including API (AWS AppSync), Storage (Amazon DynamoDB and Amazon S3), Functions (AWS Lambda), and Hosting. After running amplify init you can run the following to start a mock server:
$ amplify mock
Amplify libraries when configured for these categories can use the local mocked endpoints for testing your application. When a mock endpoint is running the CLI will update your aws-exports.js or awsconfiguration.json to use the mock server. After the mock server is stopped they will be updated to use the cloud endpoint after you have run an amplify push. For more details see the usage section.
Custom Cloudformation Stacks
The Amplify CLI provides escape hatches for modifying the backend configurations generated in the form of Cloudformation templates by the CLI. This allows you to use the CLI for common flows but also any advanced scenarios which aren’t provided in the standard category workflows.
-
For your GraphQL API generated by the Amplify CLI, you have the ability to override resolvers as well as add your own custom resolvers to add on to the CLI generated Cloudformation stacks.
-
For majority of the other categories, you can locally edit and manage the Cloudformation file generated by the CLI in the
amplify/backend/<category>/<cloudformation-template.json/yml>location. Read more about Cloudformation -
For adding and deploying a Cloudformation stack for an AWS Service not supported by the Amplify CLI currently, go through the following steps:
- Modify
amplify/backend/backend-config.jsonin your project:{ "<custom-category-name>": { "<custom-resource-name>": { "service": <custom-aws-service-name>, "providerPlugin": "awscloudformation" } }, "hosting": { "S3AndCloudFront": { "service": "S3AndCloudFront", "providerPlugin": "awscloudformation" } } }
Note: You can also reference an output value from any other Amplify managed category cloudformation stack. For example, if you want to use the Amazon Cognito userpool ID generated by the auth category stack in your custom cloudformation stack, you would need to add the dependsOn block in the backend-config.json file, The above backend-config.json file would look like the following:
{
"<custom-category-name>": {
"<custom-resource-name>": {
"service": <custom-aws-service-name>,
"providerPlugin": "awscloudformation",
"dependsOn": [
{
"category": "auth",
"resourceName": "mycognitoresource", // check `amplify status` to find resource name
"attributes": [
"UserPoolId" // Check Output Value of the resource specific cloudformation file to find available attributes
]
}
]
}
},
"hosting": {
"S3AndCloudFront": {
"service": "S3AndCloudFront",
"providerPlugin": "awscloudformation"
}
}
}
- Under
amplify/backendfolder, make a folder structure like the following:amplify \backend \<custom-category-name> \<custom-resource-name> parameters.json template.json \hosting parameters.json template.jsontemplate.jsonis a cloudformation template, andparameters.jsonis a json file of parameters that will be passed to the cloudformation template. Additionally, theenvparameter will be passed in to your cloudformation templates dynamically by the CLI. - To use the above mentioned attribute
UserPoolIdfrom the auth category in your custom cloudformation stack, you would need to construct the following input parameter in thetemplate.jsonfile. The CLI will be passing this input automatically from the other nested stack.
"Parameters": {
// Rest of the paramters
"authmycognitoresourceUserPoolId": { // The format out here is `<category><resource-name><attribute-name>` - we have defined all of these in the `backend-config.json` file above
"Type": "String"
}
},
- Place one parameter in
parameters.jsonnamedauthmycognitoresourceUserPoolIdwith a cloudformationFn::GetAttthat connects the output of one nested template to your custom template.
{
"authmycognitoresourceUserPoolId": { // The format out here is `<category><resource-name><attribute-name>` - we have defined all of these in the `backend-config.json` file above
"Fn::GetAtt": [
"authmycognitoresource", // check `amplify status` to find resource name in the category auth
"Outputs.UserPoolId"
]
}
}
- Run
amplify env checkout <current-env-name>to populate the CLI runtime files and make it aware of the newly added custom resources
Multiple Frontends
Use the amplify pull command to share the same Amplify backend across multiple frontends (e.g, a React and Android app). Users have an option to pull the entire backend definition (infrastructure templates and metadata) or only the metadata (e.g. the aws-exports.js or amplifyconfiguration.json file) required to connect to the backend. If you’re building a mobile and web app in separate repositories, the recommended workflow is to keep the backend definition (the amplify folder) in only one of the repositories and pull the metadata (the aws-exports or amplifyconfiguration.json file) in the second repository to connect to the same backend.
Workflow
This workflow outlines the steps required to share a backend across two (or more) frontends. This example scenario is for a team building an Android and React app.
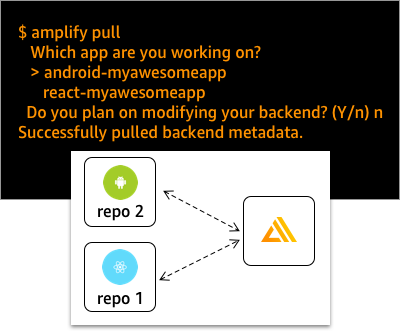
-
Initialize a backend for your React app. This will create an Amplify project and backend environment that is accessible in the Amplify Console (by running
amplify console).$ cd my-react-app $ amplify init ? Enter a name for the project: ecommerce ? Choose the type of app that you're building: react $ amplify add api $ amplify push -
Make your frontend changes and commit the code to Git. Your Git repository now stores the
amplifyfolder which contains the definition of your infrastructure. -
Reference the backend from your Android app using the
amplify pullcommand. Choose ‘No’ when asked if you want to modify or add new categories to your backend. This will put theamplifyconfigurationto your src folder only. Choosing ‘Yes’ will work, however your backend definition will now be stored in two separate repositories leading to unintended consequences with multiple sources of truth.$ cd my-android-app $ amplify pull ? Which app are you working on? > ecommerce mysecretproject ? Choose the type of app that you're building: android ? Do you plan on modifying this backend?: n Successfully pulled backend environment dev from the cloud. Run 'amplify pull' to sync upstream changes.
Environments and Teams
Concepts
When you initialize a project, you create an Amplify backend environment. Every Amplify backend environment is a container for the categories added to your project. To deploy updates to an environment, run amplify push. In teams where multiple members are working on the same backend, it is good practice to run amplify pull to fetch changes from upstream before beginning work on new backend features. View the list of backend environments in your cloud project by visiting the Amplify Console.
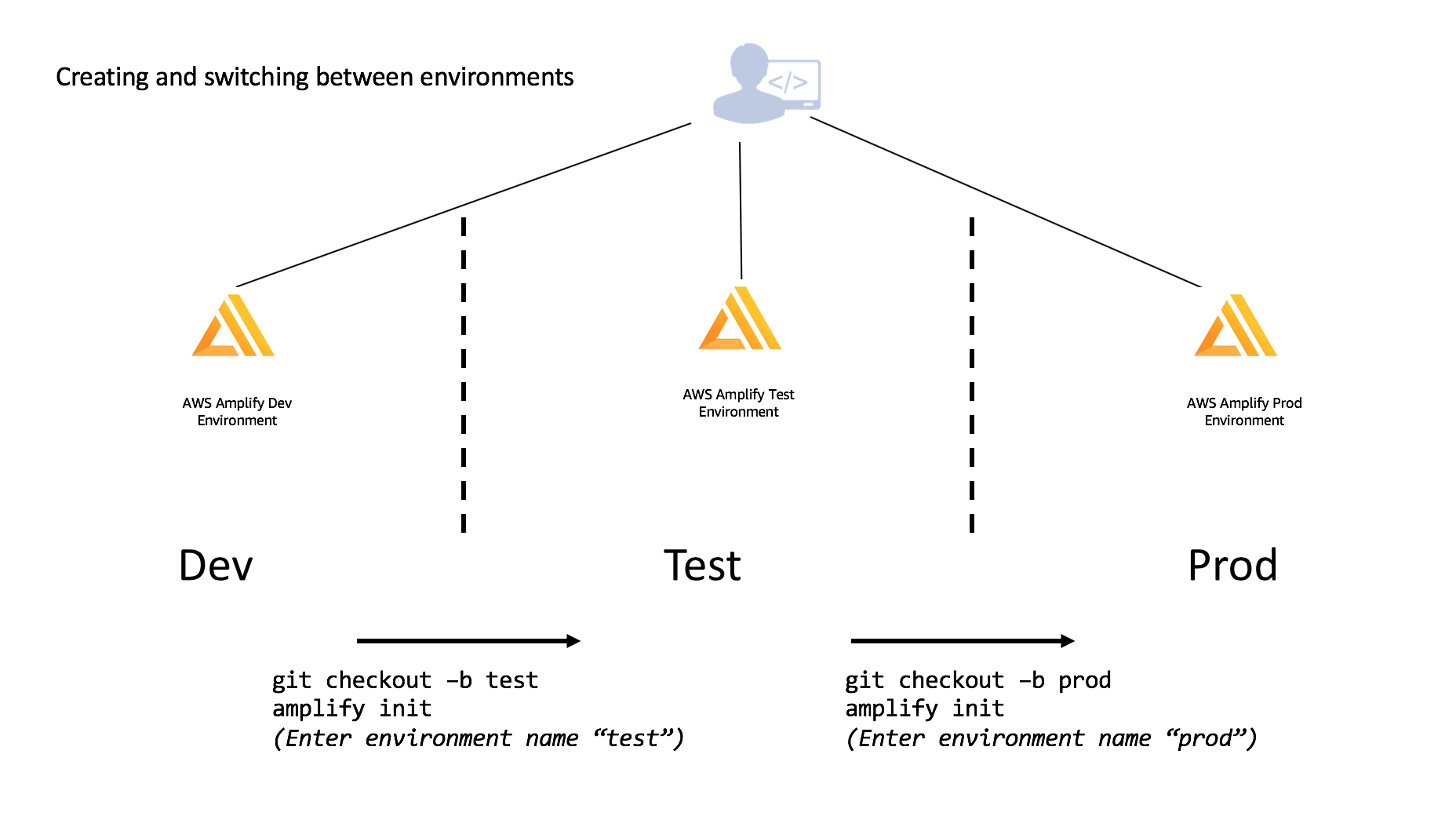
For multiple environments, Amplify matches the standard Git workflow where you switch between different branches using the env checkout command - similar to running git checkout BRANCHNAME, run amplify env checkout ENVIRONMENT_NAME to switch between environments. The diagram below shows a workflow of how to initialize new environments when creating new git branches.
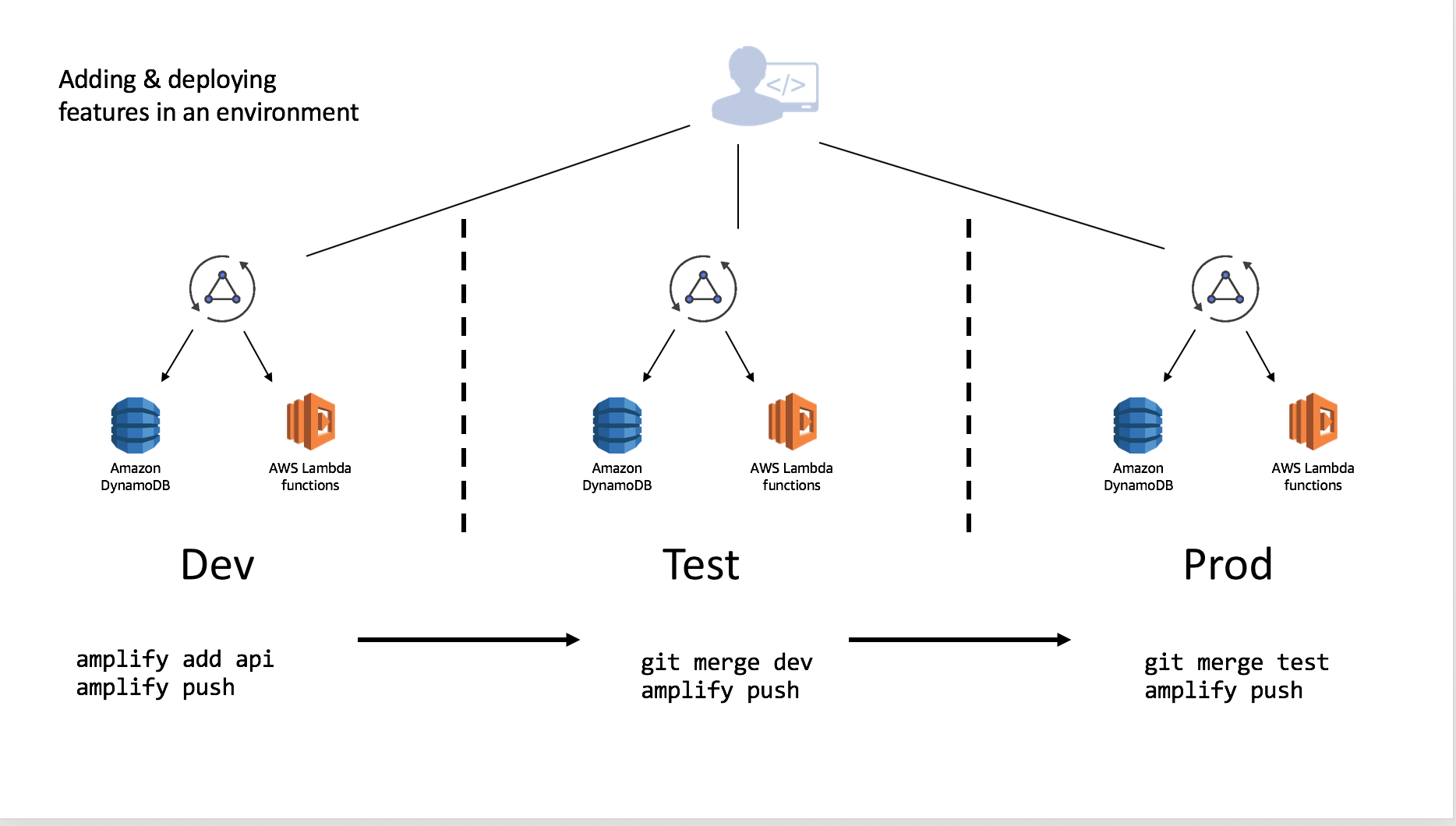
You can independently add features to each environment which allows you to develop and test before moving them to different stages. Using the same example above of Dev being the base which Test and Prod were derived, you could add (or remove) features and merge & deploy accordingly once you are comfortable with your setup.
This can be done in an iterative manner as you work through your deployment pipeline:
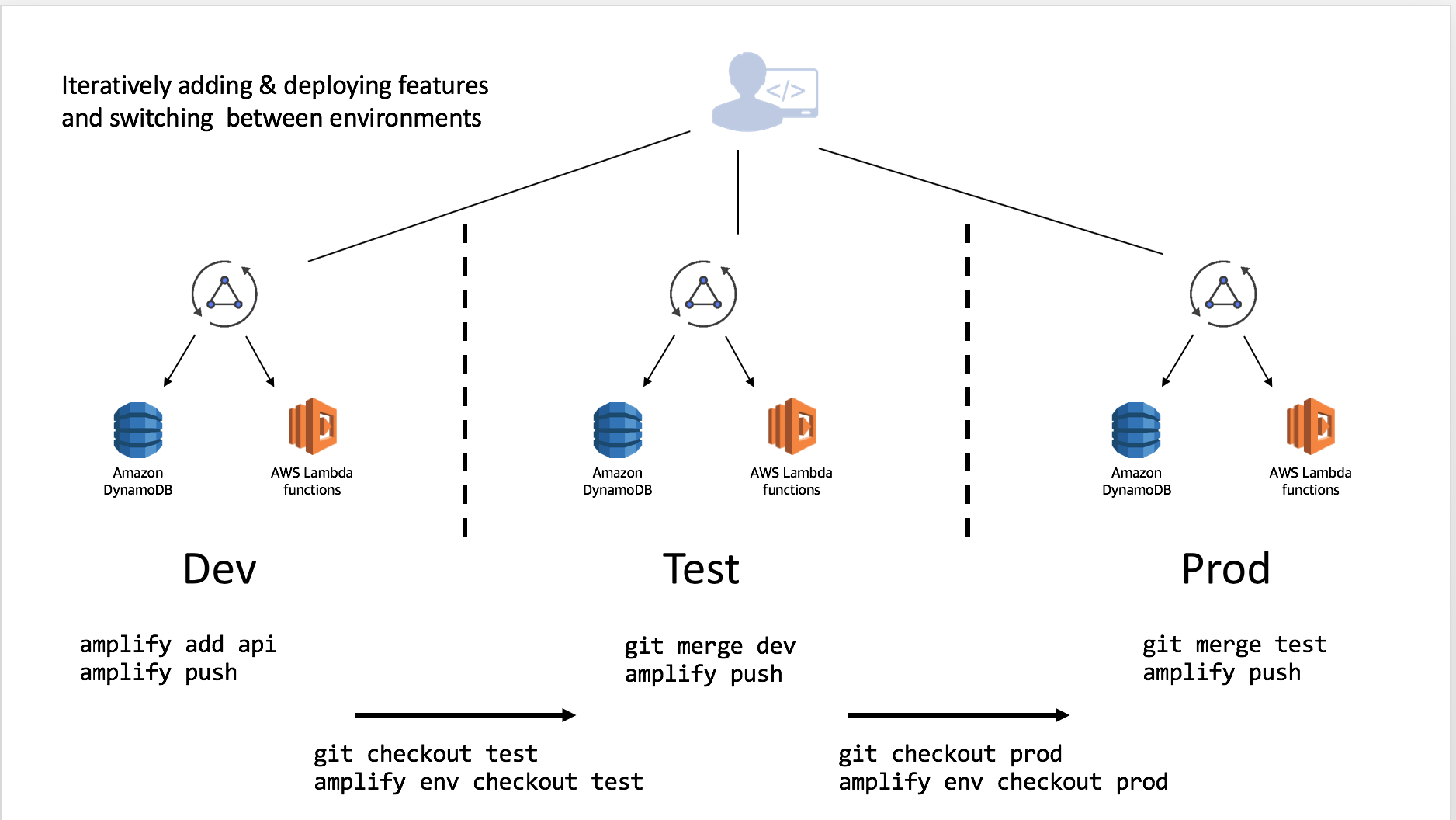
Multiple developers on a team can also share and manipulate the environment as well by using the credentials in the account. For instance suppose they wanted to test a change to the API without impacting the Test or Prod deployments. This will allow them to test the configured resources and, if they have been granted appropriate CloudFormation permissions, they can push resources as well to the backend with amplify push.
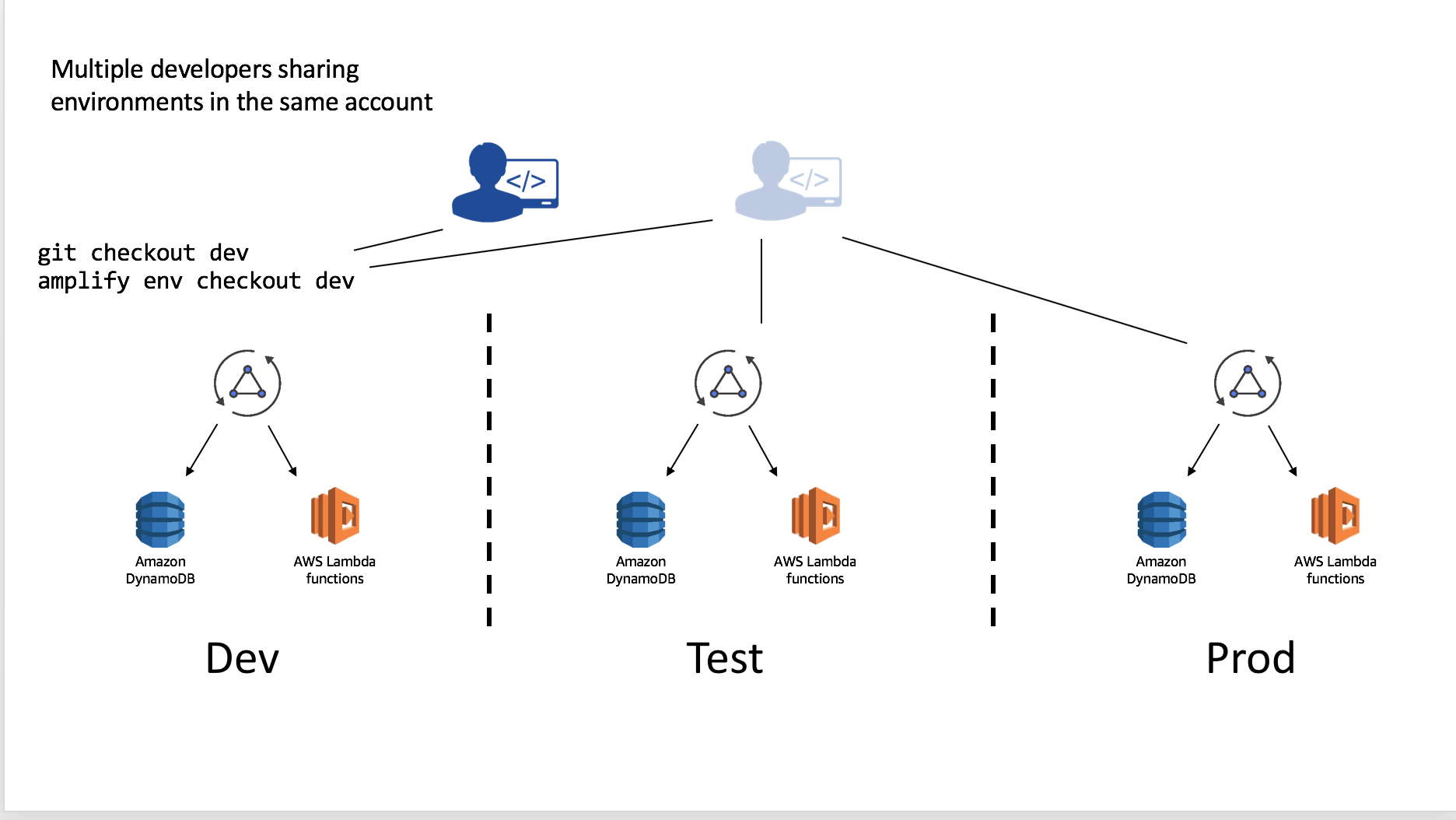
You can alternatively, have developers setup their own isolated replica of these environments in different AWS account. To do this simply:
- Clone the existing project
- Run
amplify env addand set up a new environment (e.g. “mydev”) with that developer’s account and AWS profile - Deploy with
amplify push
This workflow can be used to share complete Amplify projects with people outside of your organization as well by committing the project into a Git repository. If you are doing this remove (or add to the .gitignore) the team-provider-info.json which is located in the amplify directory. You can learn more about this file here.
Continuous deployment and Hosting
The Amplify CLI supports continuous deployment and hosting with AWS Amplify Console as well as Amazon S3 and CloudFront. You can use the multi-environments feature of the Amplify CLI with the Amplify Console for a fully managed continuous deployment solution. Learn more in the official documentation.
Setting up master and dev environments
Create a Git repository for your project if you haven’t already. It is recommended managing separate Git branches for different environments (try to have the same branch name as your environment name to avoid confusion). From the root of your project, execute the following commands:
$ amplify init
? Enter a name for the environment master
// Provide AWS Profile info
// Add amplify categories using `amplify add <category>`
$ git init
$ git add <all project related files>
$ git commit -m "Creation of a master amplify environment"
$ git remote add origin git@github.com:<repo-name>
$ git push -u origin master
Note: When you initialize a project using the Amplify CLI, it appends (if a gitignore file exists at the root of the project) or creates one for you (if a gitignore file doesn’t exist at the root of your project), with a list of recommended files to check in from the Amplify CLI generated list of files, into your Git repository.
Once you have your ‘master’ branch setup in Git, set up a ‘dev’ environment in your Amplify project (which would be based on your ‘master’ environment), and then walk through the following steps to create a corresponding git branch for it.
$ amplify env add
? Do you want to use an existing environment? No
? Enter a name for the environment dev
// Provide AWS Profile info
This will set up another environment for the project in the cloud. The backend-configs and resources are now cloned from the ‘master’ environment. Run amplify push to provision all the AWS resources for your new environment (dev).
Now push the changes to the ‘master’ branch (you would just see changes to the team-provider-info.json file - when running a git status command, which has cumulative stack information for all the project environments which are useful when you want to share the same backend within a team). After this, let’s create a new git branch - ‘dev’ corresponding to the new environment we just created.
$ git add .
$ git commit -m "Creation of a dev amplify environment"
$ git push -u origin master
$ git checkout -b dev
$ git push -u origin dev
Team workflow
Sharing a backend environment within a team
There are two ways to work with Amplify backend environments within a team:
- Team members working on their own sandbox environments (Recommended)
- Team-members sharing the same dev backend to work on
Team-members working on their own sandbox environments (Recommended)
Now you have two independent environments (master & dev) in the cloud and have corresponding git branches with your amplify backend infrastructure code on Git. Suppose a team member wants to work on the same Amplify project, add some features to it and then push changes to the dev environment to test some changes. They would perform the following steps:
$ git clone <git-repo>
$ cd <project-dir>
$ git checkout -b mysandbox
$ amplify env add
? Do you want to use an existing environment? No
? Enter a name for the environment mysandbox
// Rest of init steps
// Add/update any backend configurations using amplify add/update <category>
$ amplify push
$ git push -u origin mysandbox
Next, suppose the team-member wants to move these changes to dev and master environments/branches:
$ git checkout dev
$ amplify env checkout dev
$ git merge mysandbox
$ amplify push
$ git push -u origin dev
After testing that everything works fine in the dev stage, you could now merge dev to the master git branch:
$ git checkout master
$ amplify env checkout master
$ git merge dev
$ amplify push
$ git push -u origin master
In this approach, you can consider the git branches (dev & master) as the source of truth and all the team members should work off the branches and keep their workspaces in sync.
Team-members sharing the same dev backend
You have two independent environments (master & dev) in the cloud and have corresponding git branches with your amplify backend infrastructure code on Git. Suppose all team members want to work on the same Amplify project and push backend related changes to the same dev environment to test their changes. Each team member would run the following:
$ git clone <git-repo>
$ cd <project-dir>
$ git checkout dev
$ amplify init
? Do you want to use an existing environment? Yes
? Choose the environment you would like to use:
❯ dev
master
// The rest of init steps
// Add/update any backend configurations using amplify add/update <category>
$ amplify push
$ git push -u origin dev
Since the team is sharing the same dev backend, periodically team members would need to pull in changes which their team members pushed for the dev environment to be in sync. Let’s pull in the changes from the dev branch & environment.
$ cd <your-project>
$ git checkout dev
$ amplify init
? Do you want to use an existing environment? Yes
? Choose the environment you would like to use:
❯ dev
master
$ amplify pull
$ git pull origin dev
Sharing projects outside the team
Inside the amplify/ dir file-structure you will observe a team-provider-info.json file which contains a structure similar to the following:
{
"dev": {
"awscloudformation": {
"AuthRoleName": "multenvtest-20181115101929-authRole",
"UnauthRoleArn": "arn:aws:iam::132393967379:role/multenvtest-20181115101929-unauthRole",
"AuthRoleArn": "arn:aws:iam::132393967379:role/multenvtest-20181115101929-authRole",
"Region": "us-east-1",
"DeploymentBucketName": "multenvtest-20181115101929-deployment",
"UnauthRoleName": "multenvtest-20181115101929-unauthRole",
"StackName": "multenvtest-20181115101929",
"StackId": "arn:aws:cloudformation:us-east-1:132393967379:stack/multenvtest-20181115101929/fc7b1010-e902-11e8-a9bd-50fae97e0835"
}
},
"master": {
"awscloudformation": {
"AuthRoleName": "multenvtest-20181115102119-authRole",
"UnauthRoleArn": "arn:aws:iam::345090917734:role/multenvtest-20181115102119-unauthRole",
"AuthRoleArn": "arn:aws:iam::345090917734:role/multenvtest-20181115102119-authRole",
"Region": "us-east-1",
"DeploymentBucketName": "multenvtest-20181115102119-deployment",
"UnauthRoleName": "multenvtest-20181115102119-unauthRole",
"StackName": "multenvtest-20181115102119",
"StackId": "arn:aws:cloudformation:us-east-1:345090917734:stack/multenvtest-20181115102119/3e907b70-e903-11e8-a18b-503acac41e61"
}
}
}
This file is to be shared between team members, so that they have the ability to push/provision resources to the same Cloudformation stack and that way teams can work in a push/pull way and can always be in sync with the latest state of the project in the cloud.
Note: Team members would only be able to push to a stack only if they have the correct credentials (access key/secret keys) to do so.
If you want to share a project publicly and open source your serverless infrastructure, you should remove or put the amplify/team-provider-info.json file in gitignore file.
Quick Tips
- git and Amplify CLI work well hand in hand (ideally a CI tool should be used to automate this process - amplify CLI now provides headless support for its init/push commands. Check out https://github.com/aws-amplify/amplify-cli/tree/multienv/packages/amplify-cli/sample-headless-scripts for examples)
- git checkout
& amplify init (to initialize the env based on the git branch) should go hand in hand - git pull & amplify pull should go hand in hand
- git push & amplify push should go hand in hand
Environment related commands
- amplify env add
Adds a new environment to your Amplify Project - amplify env list [–details] [–json]
Displays a list of all the environments in your Amplify project - amplify env remove
Removes an environment from the Amplify project - amplify env get –name
Displays the details of the environment specified in the command - amplify env pull
Pulls your environment from the cloud without impacting any local backend edits. Add the--restoreflag to overwrite your local backend edits (operates like theamplify pullcommand). - amplify env import
Imports an already existing Amplify project environment stack to your local backend. Here’s a sample usage of the same
#!/bin/bash
set -e
IFS='|'
AWSCLOUDFORMATIONCONFIG="{\
\"Region\": \"us-east-1\",\
\"DeploymentBucketName\": \"mytestproject-20181106123241-deployment\",\
\"UnauthRoleName\": \"mytestproject-20181106123241-unauthRole\",\
\"StackName\": \"mytestproject-20181106123241\",\
\"StackId\": \"arn:aws:cloudformation:us-east-1:132393967379:stack/mytestproject67-20181106123241/1c03a3e0-e203-11e8-bea9-500c20ff1436\",\
\"AuthRoleName\": \"mytestproject67-20181106123241-authRole\",\
\"UnauthRoleArn\": \"arn:aws:iam::132393967379:role/mytestproject67-20181106123241-unauthRole\",\
\"AuthRoleArn\": \"arn:aws:iam::132393967379:role/mytestproject67-20181106123241-authRole\"\
}"
PROVIDER_CONFIG="{\
\"awscloudformation\":$AWSCLOUDFORMATIONCONFIG\
}"
AWS_CONFIG="{\
\"configLevel\":\"project\",\
\"useProfile\":true,\
\"profileName\":\"default\"\
}"
amplify env import \
--name dev \
--config $PROVIDER_CONFIG \
--awsInfo $AWS_CONFIG \
--yes
You can get the AWSCLOUDFORMATIONCONFIG from the team-provider-info.json file from your existing Amplify project.
Hosting
There are multiple ways to deploy and host your Amplify app. Two options are listed below:
AWS Amplify Console
Amazon S3 & Amazon Cloudfront
Workflow
amplify add hosting
This adds the hosting resources to the backend. The command will first prompt for environment selection, either DEV or PROD. Upon completion, the CloudFormation template for the resources is placed in the amplify/backend/hosting directory.amplify configure hosting
This command walks through the steps to configure the different sections of the resources used in hosting, including S3, CloudFront, and publish ignore. See below for more details.amplify publish
Theamplify publishcommand is designed to build and publish both the backend and the frontend of the project. In the current implementation, the frontend publish functionality is only available for a JavaScript project for static web hosting.amplify remove hosting
This removes the hosting resources locally from the backend. On your nextamplify pushthe provisioned hosting resources will get removed from the cloud.
AWS Amplify Console
The AWS Amplify Console is a continuous deployment and hosting service for Amplify web apps. Learn more.
The AWS Amplify Console provides a Git-based workflow for building, deploying, and hosting your Amplify web app — both the frontend and backend — from source control. Once you connect a feature branch, all code commits are automatically deployed to an amplifyapp.com subdomain or your custom domain. Get started »
Following are the concepts you would encounter when adding Amplify console as a hosting option for your Amplify app.
Type of deployments
If you select Amplify Console for hosting your Amplify App in the amplify add hosting flow, there are two stages you can select from as a part of the flow:
- Continuous deployment allows you to publish changes on every code commit by connecting your GitHub, Bitbucket, GitLab, or AWS CodeCommit repositories. Selecting this option would open up your AWS Amplify console where you can connect your Git repository. Once your repository is connected, run
git pushto deploy changes to both your backend and frontend in a single workflow. - Manual deployment allows you to publish your web app to the Amplify Console without connecting a Git provider. If you select this option, you will have to run the
amplify publishcommand every time you would like to see your changes reflected in the cloud.
Custom domain, redirects, and more
The amplify configure hosting command for the Amplify Console option, opens up the AWS Amplify Console browser tab for you where you can configure settings such as rewrite/redirect URL’s, password protection, custom domain.
These settings do not get replicated or cloned between environments and you’d have to configure them on a per-environment basis.
Note: Amplify Console automatically handles cache invalidation and there is no additional configurations or commands/command-line parameters required for it.
Amazon S3 & Amazon Cloudfront
The Amplify CLI provides you the option to manage the hosting of your static website using Amazon S3 and Amazon Cloudfront directly as well. Following are the concepts you would encounter when adding S3 & Cloudfront as a hosting option for your Amplify app.
Stages
If you select Amazon S3 & Amazon Cloudfront for hosting your Amplify App in the amplify add hosting flow, there are two stages you can select from as a part of the flow:
- DEV: S3 static web hosting
- PROD: S3 and CloudFront
It can take time to provision a CloudFront Distribution across the global CDN footprint, in some cases 15 minutes or more. Therefore the Amplify CLI provides a DEV configuration with an S3 static site only when prototyping your application; and a PROD configuration when you are ready to deploy in production. Note that the DEV stage using S3, your static site would not have HTTPS support and hence only recommended for prototyping your app.
Amazon CloudFront service can also be added or removed in your Amplify project later on top of your Amazon S3 bucket by using the amplify hosting configure command. Note that if the hosting S3 bucket is newly created in regions other than us-east-1, you might get the HTTP 307 Temporary Redirect error in the beginning when you access your published application through CloudFront. This is because CloudFront forwards requests to the default S3 endpoint (s3.amazonaws.com), which is in the us-east-1 region, and it can take up to 24 hours for the new hosting bucket name to propagate globally.
For more information of the Amazon S3 and Amazon CloudFront, check their docs: S3 static web hosting CloudFront DEV Guide
Cache Invalidation
If you select Amazon S3 & Amazon Cloudfront for hosting your Amplify App in the amplify add hosting flow, the frontend build artifacts will be uploaded to the S3 hosting bucket, and then if Amazon CloudFront is enabled along with it, the amplify publish command executed with the --invalidateCloudFront or -c flag will send an invalidation request to the Amazon CloudFront service to invalidate its cache.
Advanced Configurations
The amplify configure hosting command walks through the steps to configure the different sections of the resources used when hosting through Amazon S3 & Amazon Cloudfront. Following are the available configurable options:
Website
Configures the S3 bucket for static web hosting. You can set the index doc and error doc references by configuring this option. Both are set to beindex.htmlby default.CloudFront
Configures the CloudFront content delivery network (CDN). You can configure TTLs (Time To Live) for the default cache behavior, and configure custom error responses.Publish
Configures the publish ignore patterns (similar to a .gitignore file in your git based project) for the publish command. The publish command will ignore these set of directories and files in the distribution folder that have names matching the patterns.